Developer Best Practices
- David Burdick (Unlicensed)
- Bruce Hoff
- Geoff Shannon (Unlicensed)
Development Process
The below sections describe how you should develop for Synapse.
Code Contribution
Fork, Pull Request & Code Review
You should start by forking the Sage-Bionetworks Synapse-Repository-Services repository (Central) so you have a clone of it in your GitHub account.
https://help.github.com/articles/fork-a-repo
Once you have committed changes to a branch in your forked repository (see Git Branching Model below), you will need to create a Pull Request and identify another developer at Sage to do a code review of your changes.
https://help.github.com/articles/using-pull-requests
The code review should be a sit down meeting for any significant changes, so send that developer a meeting request via Google Calendar. Digital code reviews can be done for small changes. If you don't know the best person to review your code, ask Mike. As the developer you should explain the design decisions you made. As a reviewer yourself, you should make sure that best practices were followed, proper libraries and dependencies were used, that the design and logic was sound, and that the changes are adequately tested (See Testing Philosophy below). Pull requests should be able to be automatically merged at the time of their creation–thus make sure you pull and merge changes from the Central repo to your forked repository before creating the request. If a pull request/code review has not been completed after a time and conflicting changes have since been pulled into the Central repo, you must merge those changes into your repo and alter your pull request (you can also send your reviewer an email telling them how lazy they are).
How to get your develop code into the central repository, step by step
If you are concerned that the way you committed your code isn't the way that you want it to look in the actual history, then you should check out the wiki page on Cleaning Up Your Git History.
Read the Git Branching Model document for details!
Let's say you are working on a local branch called "PLFM-123" branched off of "develop" which was pulled from your private fork of Synapse-Repository-Services. Now you want to get your completed code back into the central repository. Here's how:
- mvn clean install -Dorg.sagebionetworks.database.drop.schema=true (to get a clean build of your changes)
- git checkout develop
- git pull upstream
- git checkout PLFM-123
- git rebase develop
- resolve conflicts
- get a clean build
- git push origin develop
- issue a pull request (see above linked article)
- create meeting request to do a code review with another Platform Team member (developer or product manager)
- reviewer merges the pull request
Important!
If you don't have your code-to-be-committed in a separate branch (i.e. you have been working directly in the develop branch), then this process is SLIGHTLY DIFFERENT!
- git fetch upstream
- git rebase upstream/develop
- resolve conflicts
- git push origin develop # same from here on out too
For information about this process uses rebase instead of merge differ, and why using merge is okay in the first instance and not in the second check out the history page in Git for Computer Scientists. If you have more questions, start a wiki page about it and ask someone!
Git Branching Model
Developers are expected to follow the develop/master branching model as described in this article: http://nvie.com/posts/a-successful-git-branching-model/. Feature development branches should be merged back to the develop branch as soon as possible! It is not ok to keep completed features in a developer branch and then merge them at the end of a development sprint.
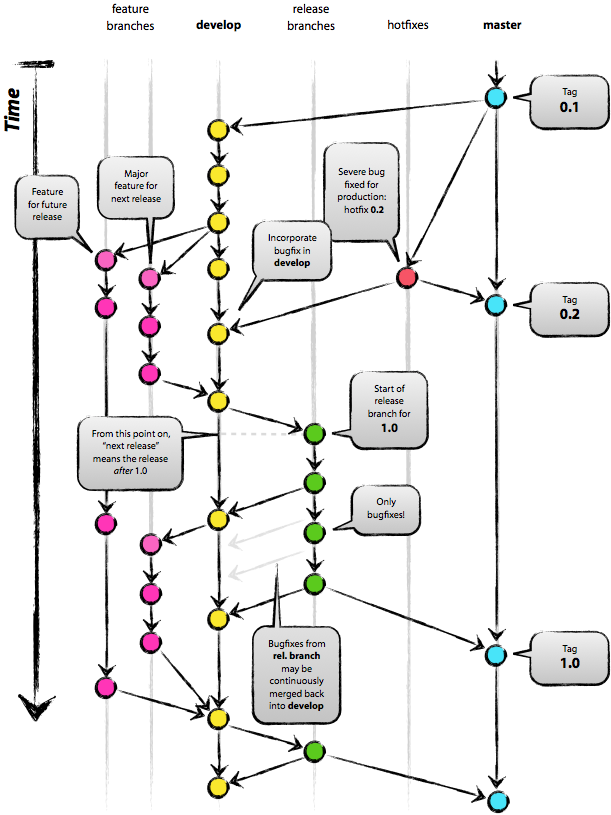
Git Commands for this workflow
Easier: Use GitFlow for this workflow
GitFlow is a command line tool that makes the above developer workflow easier.
Commands: https://github.com/nvie/gitflow/wiki/Command-Line-Arguments
Code release schedule
Code is not really done until it is in the hands of end users. Sage does not have a separate operations team. Instead, we have a unified dev-ops team in which members rotate into 2 week long roles where they are on point to address qa, deployment operations, and release management. See Deployment / QA Team for details. The following sections describe the routes developers can take to get code into production and their responsibilities when taking each route.
Standard Release Cycle
This should be the default and most common path for code to reach production servers. The process starts when code is checked into the develop branch on the Sage Bionetworks orgin repository. (Note, this process is achieved by a developer issuing a pull request and another developer doing a code review and accepting the pull request as described above.) If you have code that you want checked in but is not ready to enter the deployment pipeline it should go into a branch until it is ready to enter the deployment process. However, developers should try to create frequent small and stable check-ins to develop in order to avoid large merges. Launch flags or other design patterns may allow incomplete features to safely enter the main development stream earlier rather than later.
Accepting a pull request into the "develop" branch in the Sage-Bionetworks github repository will trigger an automated build and test run by our continuous build system. It is the developer's top responsibility to respond to any test failures and fix the build as quickly as possible if it breaks on his check in. Once the automated build passes it is assumed the code change is safe to enter the deployment pipeline. Every Monday morning the deployment team will create a new release branch from develop (let's assume it's called 1.n). Developers should not merge in new pull requests into develop Monday morning until they hear from the deployment team that the release branch has been created. The deployment team will then create an initial pre-production build by merging from the release branch to master and giving the code a tag (which would be 1.n.0). This build is then deployed to staging where it is subjected to smoke testing and any other automated testing that spans multiple projects. Sage follows a blue-green deployment pattern where we have multiple identical environments, and production and staging rotate though new environments every week. During the week after a check in while a code change has reached the staging environment, it is the developer's responsibility to do some quick manual QA to validate that their previous week's code changes are performing as expected. The deployment team will also do independent QA of the release on staging. Developers are encouraged to find end users and co-opt them in validating the changes on staging.
The following Monday evening, the staging environment will be switched over to become the new live production system. At this point your code changes are in the hands of end users and adding value!
Pre-release patch
During the week a release is living on staging, it is expected that minor bug fixes may be applied to the release as patches. Patches can not contain schema changes, and they should not contain major new features or API changes unless discussed with management. It must be deployable by simply dropping new .war files into an existing environment with no data migration or new environment configuration needed. However we do expect minor bug fixes and feature enhancements uncovered by testing the release on staging to be put in. A developer gets code into a patch by issuing a pull request on the release branch that must be approved by a member of the deployment team. Another engineer may be brought in to contribute to the code review if the deployment team is unable to do this task, however, they must be in the loop that the change is going into the release branch. Once this occurs it is the original developer's responsibility to merge the change into develop, which he may do without a code review. The deployment team will potentially batch up multiple check-ins and periodically deploy new patches to staging. These patches will result in incrementing the third digit of the released artifacts. Once deployed, the developer should validate the changes on the staging server.
Post-release patch
Once a release is put into production non-essential patches should be avoided. If it is necessary to issue a patch to the production environment the procedure is the same as above with the following two changes:
- The engineer must merge the changes into both develop branch and the next release branch supporting staging. We don't want the patch to disappear for a week!
- A manager must approve the need for a post-release patch.
Hotfix
Anything that does not fit one of the three release patterns defined above is to be avoided if at all possible. The hotfix pattern shown above in the figure should not be needed if the tip of the release branches is always in a good state ready for deployment. If there are extreme reasons why some other approach than the three above is needed, it must be discussed with management. Expect a discussion of risks vs. benefits and to be on call to recover from any problems introduced by non-standard approaches.
Testing Philosophy
Basic Tenets
- Unit test all business logic
- Integration test that connections across systems function as expected. Integration tests should NOT test business logic!
- Smoke test (aka Selenium) only that configuration of a system is correct
Other
- Use Mockito and dependency injection to isolate unit test functionality.
- For SynapseWebClient mocking specifics, see SWC Developer Best Practices
- All bug fixes should be accompanied by a test that provokes the old bug.
- (this is just a start, please add more)
To make a breaking API change to a web service
A breaking API change can be a web service which is removed, a change to request parameters, or a change to a request or response body.
If we can reasonably be sure that a service change will not affect existing clients or applications, the change can be made freely. (This is usually the case with new services, not yet adopted by users.) . Otherwise breaking API changes should proceed along the following steps:
- Note the change in the web service documentation. A service or schema field to be removed can be marked as 'deprecated'.
- Open Jira issues to modify clients to adopt to the change (e.g., to stop using a deprecated service).
- After clients are modified, use the Synapse data warehouse to verify users have updated clients, and hence are no longer affected by the planned change. If there are just a few lingering users of out of date clients, it should be the judgment of the Synapse Product Manager as to whether it's OK to proceed.
- Proceed with the breaking API change.
To insure against breaking API changes
As part of the weekly deployment process, the integration test suites for the currently supported R and Python clients are run against the new stack, which is 'staged' for release. Test failures will occur only if a breaking API change has been introduced to the back end, without following the procedure described above. If so, either (1) the breaking change is to be removed from the staged back-end or (2) the client(s) must be updated to work with the back-end change. Due to the time scale of back end release (weekly) versus client adoption (on the order of months), doing (2) will risk causing failure of some installed client. Therefore (2) should only be done when (a) there is a strong driver for the API change and (b) the chance of affecting existing workloads is low. Such a decision should reflect the judgment of the Synapse Product Manager.