WIP: Current design subject to changes
The epic SWC-4488 - Getting issue details... STATUS groups the issues submitted about a new feature request that revolves around exposing from the the synapse API some basic statistics about projects. In the following the list of relevant tickets in the epic:
Introduction
It is clear that there is the need for the platform to provide some statistics about the usage of the data within synapse: discussions around various aspects and statistics to gather and expose have been going on for several years.
There are different statistics that the synapse projects owner and administrators are currently interested in and different levels of understanding of what should be exposed by the API. In particular there are 3 main points of discussion that are related but need clarifications:
- Downloads Count
- Page Views
- Data Breaches/Audit Trail
Downloads Count
This is the main statistic that the users are currently looking for, it provides a way for project owners, funders and data contributor to monitor the interest over time in the datasets published in a particular project, which then reflects on the interest on the project itself and it is a metric of the value provided by the data in the project. This kind of data is related specifically to the usage of the platform by synapse users, since without being authenticated the downloads are not available. This is part of a generic category of statistics that relates to the entities and metadata that is stored in the backend and it's only a subset of aggregate statistic that can be exposed (e.g. number of projects, users, teams etc).
Page Views
This metric is also an indicator to monitor the interest but it plays a different role and focuses on the general user activity over the synapse platform as a whole. While it might be an indicator for a specific project success it captures a different aspect that might span to different type of clients used to interface on the Synapse API and that include information about users that are not authenticated into synapse. For this particular aspect there are tools already integrated (E.g. google analytics) that collect analytics on the user interactions. Note however that this information is not currently available to the synapse users, nor setup in a way to produce information about specific projects pages, files, wikis etc.
Data Breaches/Audit Trail
Another aspect that came out and might seem related is the identification of when/what/why of potential data breaches (e.g. a dataset was released even though it was not supposed to). This relates to the audit trail of users activity in order to identify potential offenders. While this information is crucial it should not be exposed by the API, and a due process is in place in order to access this kind of data.
Project Statistics
With this brief introduction in mind this document focuses on the main driving use case, that is:
- A funder and/or project creator would like to have a way to understand if the project is successful and if its data is used.
There are several metrics that can be used in order to determine the usage and success of a project, among which:
- Project Access (e.g. page views)
- Number of Downloads
- Number of Uploads
- User Discussions
Current Situation
Currently the statistics about a project are collected in various ways mostly through the Data Warehouse, using /wiki/spaces/DW/pages/796819457 of the data collected to run ad-hoc queries for aggregations as well as through dedicated clients (See Synapse Usage Report).
- The process is relatively lengthy and requires non trivial technical skills
- The data is limited to a 6 months window, the current solution to this problem is to store incremental updates on an external source (cvs file on S3)
- The data cannot be easily integrated in the synapse portal or other components (in some cases the files are manually annotated with the number of downloads)
- The system has an all or nothing policy for accessing the data, that is (for good reason) only accessible to a specific subset of synapse employees, this does not allow the users of the synapse platform to access this kind of data without asking a synapse engineer
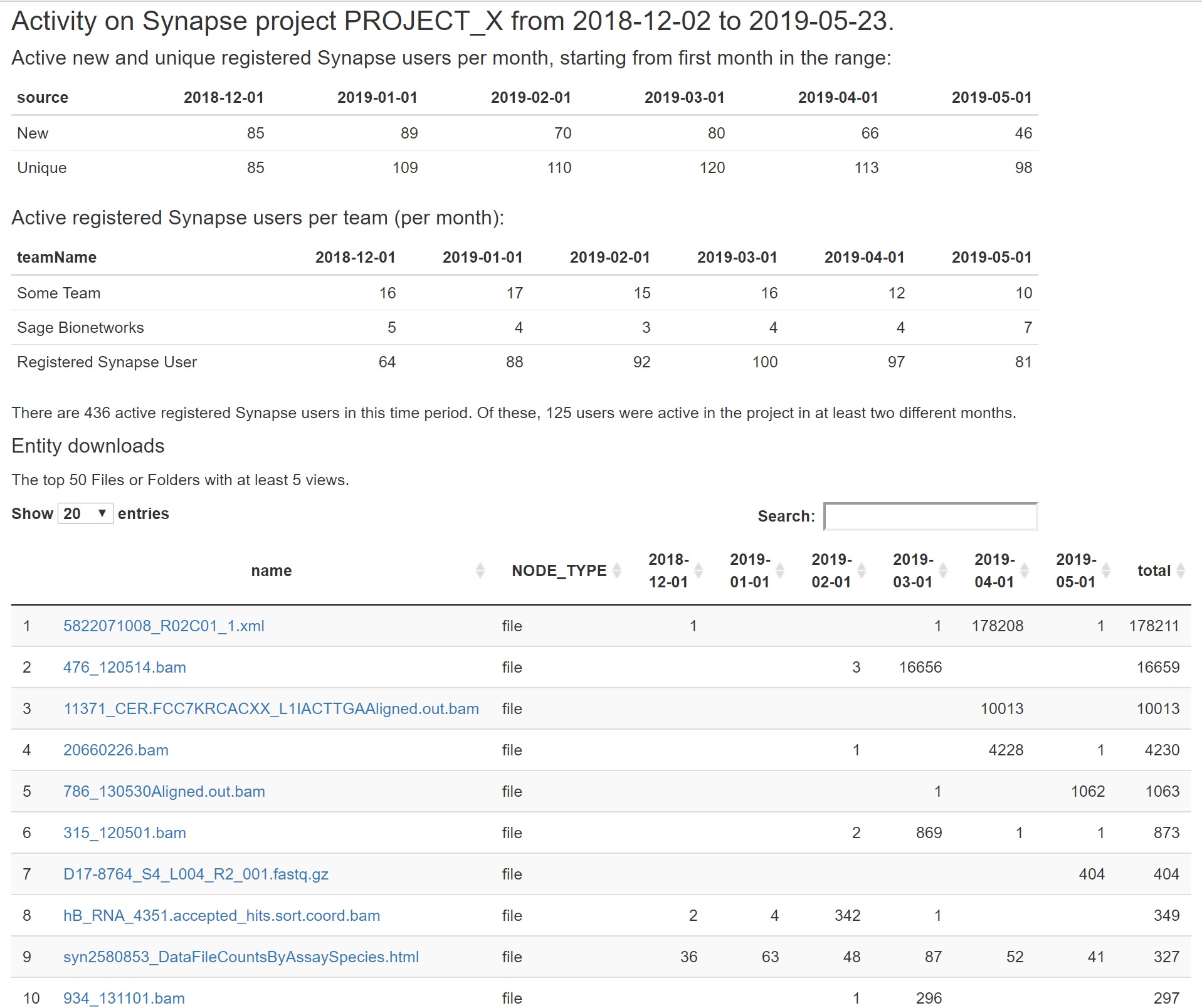
An example of usage report generated using the Synapse Usage Report written by Kenny Daily using the data warehouse:
First Phase Proposal
In a first phase we want to have a minimal set of statistics that are exposed from the synapse platform API that provides a way to fulfill the use case. In particular we identified the following aspects that allows to have an initial implementation that can be extended in a later moment if needed:
- Expose statistics about number of download and number of uploads
- Expose statistics about the number of unique users that downloaded and/or uploaded
- Statistics are collected on a per project basis (no file level statistics)
- Statistics limited to the last 12 months
- Statistics aggregated monthly (no total downloads or total users)
- Statistics are accessible to the project owner/administrator only
- No run-time filtering
Files, Downloads and Uploads
Files in synapse are referenced through an abstraction (FileHandle) that maintain the information about the link to the content of the file itself (e.g. an S3 bucket). A file handle is then referenced in many places (such as FileEntity and WikiPage, see FileHandleAssociateType) as pointers to the actual file content. In order to actually download the content the synapse platform allows to generated a pre-signed url (according to the location where the file is stored) that can be used to directly download the file. Note that the platform has no way to guarantee that the pre-signed url is actually used by the client in order to download a file. Every single pre-signed url request in the codebase comes down to a single method getURLForFileHandle.
In the context of a project we are interested in particular to download (and/or uploads) of entities of type FileEntity and TableEntity (See What is a "download" in Synpase?) and the download request made for the associated file handles.
There are also different ways to actually get pre-signed urls for file handles that are exposed through the API. For the context of project and files download we are interested in specific operations, in particular there are several API endpoints that are used to request a pre-signed url to download the content of entities of type FileEntity (For a complete list of endpoints that reference file handles see Batch FileHandle and File URL Services):
| Endpoint | Description |
|---|---|
| Currently deprecated API, will return a 307 with the redirect to the actual pre-signed url of the file for the given entity |
/fileHandle/batch | Allows to get a batch of pre-signed urls for a set of file handles. The request (BatchFileRequest) specifically requires the id of the object that reference the file handle id and the type of the object that reference the file handle (See FileHandleAssociation and FileHandleAssociateType) |
/file/{id} | Allows to get the pre-signed url of the file handle with the given id. The request must contain within the parameters the FileHandleAssociateType and the id of the object that reference the file. Similarly to the deprecated /entity/{id}/file will return a 307 with the redirect to the pre-signed url |
/file/bulk/async/start | This is part of an asynchronous API to start a bulk download of a list of files. The api allows to monitor the background task and get the result through a dedicated file handle id that points to the zip file that can be used to download the bulk of files |
The main aspect that we want to capture is that in general any relevant file download should include the triplet associateObjectType, associateObjectId and fileHandleId (See the FileHandleAssociation) that allows us to understand the source of the file download in the context of a request.
In the following we provide some basic download statistics computed for the last 30 days worth of data (as of 06/27/2019) as reported by the data warehouse:
"direct" downloads statistics
| Included APIs | Average Daily Downloads | Max Daily Downloads |
|---|---|---|
| 2324 | 4030 |
| 67 | 245 |
"Batch and bulk" Downloads
| Association Type | Average Daily Downloads | Max Daily Downloads | Average daily users | Max daily users |
|---|---|---|---|---|
| All | 39998 | 383539 | 140 | 227 |
| FileEntity | 19963 | 367345 | 59 | 100 |
| TableEntity | 19680 | 145050 | 12 | 21 |
Proposed API Design
In general computing statistics might be an expensive operation, moreover in the future we might want to extend the API to include several different types of statistics. According to the use cases and the requirements we can potentially pre-compute statistics aggregates so that we can serve them relatively quickly, nevertheless we cannot guarantee that all type of statistics will return within a reasonable response time.
To this end we propose an API that integrates into the current /asynchronous/job API (See Asynchronous Job API) so that a client can send a request to compute certain statistics and wait for the final response polling the API for the result. This allows to offload the computation to a background worker keeping the API servers free of heavy computation. Note that the computation of certain statistics might actually be relatively short without the need of a background job (e.g. we might be able to cache the statistics for a whole project): using a worker might lead to a small delay in retrieving the statistics from a user point of view but it is probably fine for now. We might want to consider (if needed, as an optimization) to provide from the Asynchronous API the result right away without the need to offload to a background worker.
The two main objects that the statistics API will need to extend are: AsynchronousRequestBody and AsynchronousResponseBody that represent respectively the request for a background job and the response from the job (returned as part of the AsynchronousJobStatus).
Note: In the actual implementation we might have a generic SynapseStatistics interface used as a marker of any statistics request.
Request Object
ProjectStatisticsRequest
<extends> AsynchronousRequestBody
Object used to start the request for retrieving the statistics about a specific project. This object is an AsynchronousResponseBody that will be sent to the /asynchronous/job endpoint in order to start the computation of the project statistics.
| Property | Required | Type | Description |
|---|---|---|---|
| projectId | Yes | STRING | The (synapse) id of the project for which the statistics should be gathered |
| mask | No | INTEGER | Allows to define which statistics to be included in the response, similarly to the Entity Bundle Services. The supported values are as follow:
By default both are included with the mask 0x3 (0x1 + 0x2). |
{
"projectId": "syn12345"
"mask": 1
}
Response Object
ProjectStatisticsResponse
<extends> AsynchronousResponseBody
Represents the response for a job request for computing the project statistics (In response to a ProjectStatisticsRequest).
| Property | Type | Description |
|---|---|---|
| downloads | DownloadStatistics | Contains the download statistics for the project specified in the request, this is included only if the mask property in the ProjectStatisticsRequest has the 0x1 flag set. |
| uploads | UploadStatistics | Contains the upload statistics for the project specified in the request, this is included only if the mask property in the ProjectStatisticsRequest has the 0x2 flag set. |
DownloadStatistics/UploadStatistics
| Property | Type | Description |
|---|---|---|
| lastUpdatedOn | Date | Contains the last update date for the download/upload statistics, this value provide an approximation on the freshness of the statistics |
| monthly | ARRAY<StatisticsCountBucket> | An array containing the monthly download/upload count for the last 12 months, each bucket aggregates a month worth of data. The number of buckets is limited to 12. Each bucket will include the unique users count for the month. |
StatisticsCountBucket
The purpose of this object is to include information about the count of a certain metric within a specific time frame (in this case monthly):
| Property | Type | Description |
|---|---|---|
| startDate | Date | The starting date of the time frame represented by the bucket |
| count | INTEGER | The download/upload count in the time frame |
| usersCount | INTEGER | The number of unique users that performed a download/upload in the time frame of the bucket |
{
"downloads": {
"lastUpdatedOn": "2019-26-06T01:01:00.000Z",
"monthly": [{
"startDate": "2019-01-06T00:00:00.000Z",
"count": 1230,
"usersCount": 10
},
{
"startDate": "2019-01-05T00:00:00.000Z",
"count": 10000,
"usersCount": 100
}]
},
"uploads": {
"lastUpdatedOn": "2019-26-06T01:01:00.000Z",
"monthly": [{
"startDate": "2019-01-06T00:00:00.000Z",
"count": 51200,
"usersCount": 200
},
{
"startDate": "2019-01-05T00:00:00.000Z",
"count": 10000,
"usersCount": 100
}]
}
}
Endpoints
The API reuses the endpoints from the Asynchronous Job API (We could potentially add a dedicated /statistics endpoint just for clarity).
| Method | Endpoint | Request Body | Response Body | Description | Restrictions |
|---|---|---|---|---|---|
| POST | /asynchronous/job | AsynchronousJobStatus: the responseBody property in the status will contain the ProjectStatisticsResponse | Allows to submit a job to gather the download statistics for a project. The id returned by the request is used in order to get the job status. |
| |
| GET | /asynchronous/job/{id} | N/A | AsynchronousJobStatus | Allows to get the current status of the statistics job with the given id. |
Additionally we propose to have dedicated statistics endpoints to be consistent with the current API design that accepts the above requests:
| Method | Endpoint | Request Body | Response Body | Description |
|---|---|---|---|---|
| POST | /statistics/project/async/start |
| AsynchronousJobStatus | Allows to submit the job to gather the statistics for a project. The id returned by the request is used in order to the the job status. |
| GET | /statistics/project/async/get/{asyncToken} | N/A | AsynchronousJobStatus | Allows to get the current status of the statistics job with the given id |
Web Client Integration
The web client should have a way to show the statistics for a project or a specific file, some initial ideas:
- Have a dedicated menu item that leads to a statistics dashboard (should be visible only to the project owner/administrator)