...
- Constrain the set of values allowable for a particular property on a particular entity type to a set of values defined by the Synapse Ontology. E.g. the disease property must come from the set of terms that are narrower concepts than the “Disease” concept defined by the Synapse ontology. Note: one way we currently do this is via defining Enumerations in our object JSON schema, which result in the generation of Java objects containing an Enum of valid values. This is sufficient when the list of terms is relatively small and static. The ontology path is designed to support cases with 10K’s of terms allowed (e.g. any valid gene symbol), and to allow at least additive changes to the ontology without a Synapse build-deploy cycle. (Breaking changes to the Synapse ontology could also require a data migration step to make old data match the new ontology.)
- Constrain the set of values allowable for a particular clinical variable. Currently these are columns of a phenotype layer; we are in process of modeling these more explicitly as a Samples object within a dataset. In either case, we want to be able to define things like “the genes column must contain a gene as identified by the Gene Ontology”
- Use the ontology to help users find the entities or samples they are interested in. This could take the form of:
- type-ahead resolution (or other UI mechanism to limit input to a large set of strings) against all or part of the Synapse ontology
- facets linked to a portion of the Synapse ontology
- Use of synonyms and broader / narrower terms in the Synapse ontology to pre-process a search of free text and return more complete / relevant results.
- Long term only: Allow users annotating data to feed back proposed modifications to the Synapse ontology so that it improves over time.
Summary of Design
TODO: Insert picture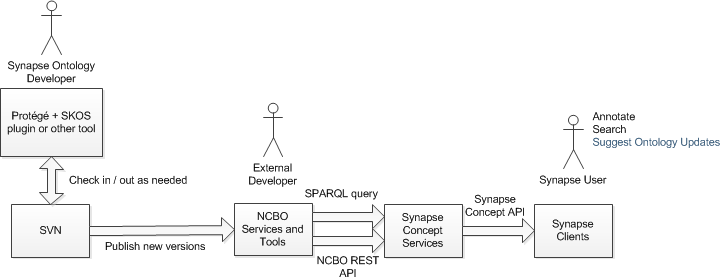
- Ontology developers can use any tool that generates / reads SKOS to update the ontology. As examples Protégé contains a SKOS plug-in, and Google Refine has a way to translate between a spreadsheet format and SKOS. We propose editing the Synapse ontology is a task done by a small number of in-house experts, who will check that ontology as SKOS into SVN, giving us versioning, merging and diff on our ontology, and setting us up for interoperability with other systems.
- We will publish Ontology in NCBO as new versions when we want to upgrade the Synapse ontology and make it available to external developers and the Synapse system. This makes the ontology available to both our own and external developers via the NCBO web services, including a SPARQL endpoint (general-purpose graph-query language). Our Google Refine project, for example, is hitting the public NCBO services to support term-reconciliation off any NCBO ontology.
- We will add a new set of Concept Services to Synapse to provide easy use of the Synapse ontology in Synapse clients. This will also insulate real-time users making these calls from a dependency on an external web service, reducing the risk of performance or availability problems. The service will not have any long-term persistence of the ontology, and is likely to work off of an in-memory cache of concepts generated from loading the Synapse ontology via the NCBO services.
- Synapse clients access Synapse Concept Services for information on Concepts.
...