Overview
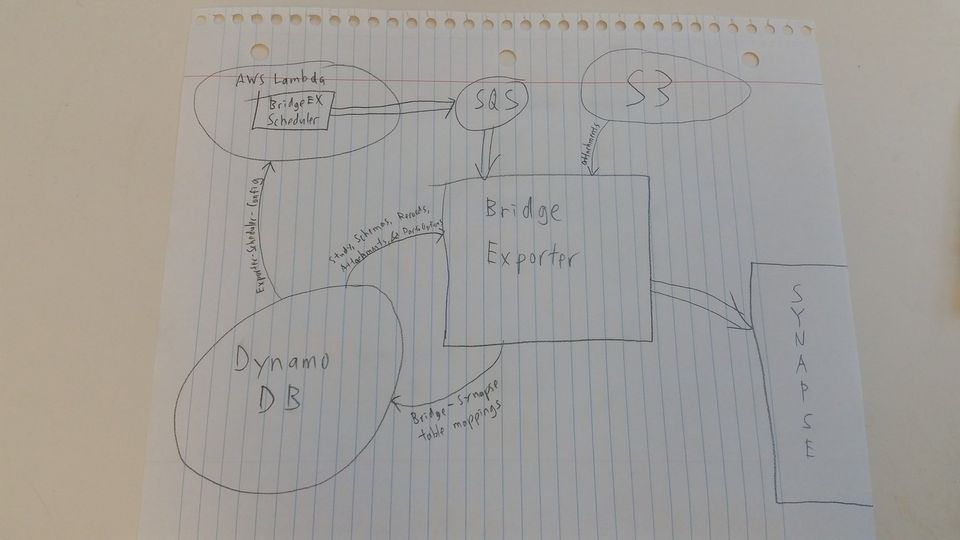
- Bridge-EX-Scheduler lives inside AWS Lambda, with a schedule configured to execute every day at 10am UTC (2am PST, 3am PDT).
- Scheduler pulls configs from DynamoDB table Exporter-Scheduler-Config, which contains the SQS queue URL, time zone, and an optional request JSON override.
- Scheduler generates the request, fills in yesterday's date, and writes the request to the SQS queue.
- Bridge-EX polls SQS, waiting for a request.
- When the request arrives, it pulls user health data records from DDB (along with study info, schemas, attachment metadata, and participant options (sharing options)), as well as attachment content from S3.
- Bridge-EX writes uploads attachments to Synapse as file handles and writes the record to a TSV (tab-separated values) file on disk.
- On completion, Bridge-EX uploads the TSVs to the Synapse tables, creating new tables as necessary.
Components
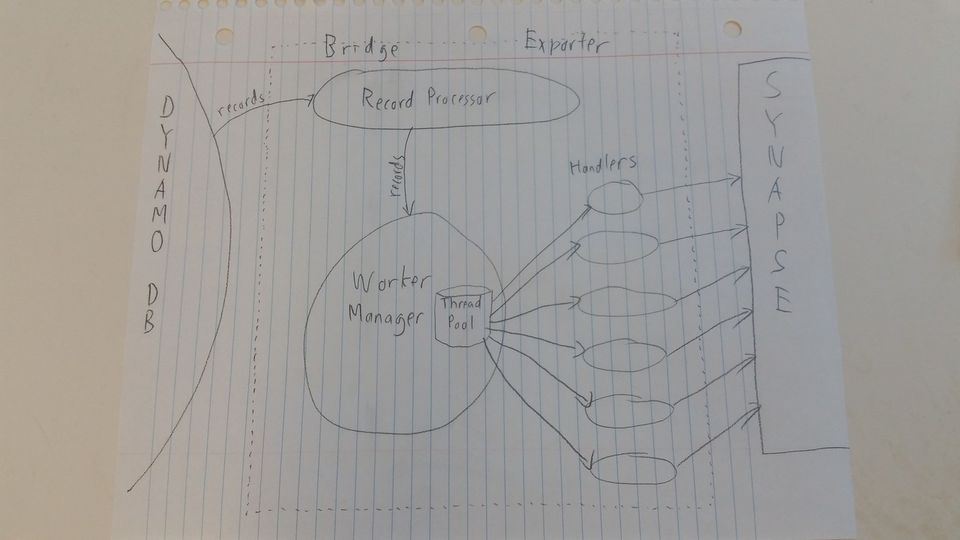
Bridge-EX components can be broken down into 3 major groups (not including Spring components and various helpers).
- Record Processor - This is the entry point into Bridge-EX. It polls SQS for a request. When a request comes in, it iterates through all health data records associated with that request, calling the Worker Manager with each record. When it's done iterating records, it signals "end of stream" to the Worker Manager.
- Worker Manager - This contains a thread pool, a collection of worker handlers, and a task queue, as well as various helper logic needed by the handlers. The Worker Manager is called for every record in a request, and queues a task onto each relevant handler. On end of stream, the Worker Manager signals to each handler to upload their TSVs to Synapse.
- Handlers - Various handlers that can be run asynchronously and in parallel. These include health data handlers, app version handlers, and legacy iOS survey handlers.
Spring Configs and Launcher
(config) AppInitializer - This is called by Spring Boot and used to initialize the Spring context and the app.
(config) SpringConfig - Annotation-based Spring config. Self-explanatory.
(config) WorkerLauncher - This is a command-line runner that Spring Boot knows about. Spring Boot automatically calls the run() method on this when it's done loading the Spring context. This is what sets up and runs the PollSqsWorker (defined in bridge-base), which in turn calls the BridgeExporterSqsCallback when it gets a request. The WorkerLauncher currently does everything single-threaded, since Bridge-EX workers are already heavily multi-threaded and we never need to run multiple Export requests in parallel.
Record Processor
(record) BridgeExporterRecordProcessor - This is the main entry point into the Exporter. This is called once for each request, with the deserialized request. This calls the RecordIdSourceFactory to get the stream of record IDs (which it then queries DDB to get the full record), the RecordFilterHelper to determine whether to include or exclude the record, and the WorkerManager to queue an asynchronous task for each record. This has a configurable loop delay to prevent browning out DDB and will log progress at configurable intervals.
(record) RecordFilterHelper - Helper function to determine if a record should be included or excluded. Criteria include: (a) sharing scope (b) study whitelist (see Redrives) (c) table whitelest (see Redrives) (d) skipping unconfigured studies. Note for sharing scope, this uses the most restrictive between the sharing scope at the time of the upload and the user's current sharing scope (with missing sharing scopes treated as "no sharing"). This is so that if a user uploads data, and then decides to withdraw, pause, or otherwise stop sharing before the data is exported, we respect their sharing scope. This has the side effect such that if we re-export data for whatever reason, any user who has since stopped sharing will not have their data exported.
(record) RecordIdSource - The Record ID Source represents a stream of record IDs. One is created for each request, and Record Processor iterates on this stream to get record IDs. This can either be a DDB query result or a record ID list from an S3 override file. Internally, the Record ID Source contains an Iterator from the backing stream and a Converter (a functional interface, used by lambdas) to extract the record ID from the elements in the backing stream and convert it to a String. The Record ID Source is itself an Iterator and implements both the Iterator and Iterable interfaces.
(record) RecordIdSourceFactory - This creates Record ID Sources. It reads the Bridge Exporter Request to determine if it needs a DDB query or an S3 override file and creates the corresponding Record ID Source.
(request) BridgeExporterSqsCallback - This callback connects the PollSqsWorker and the Record Processor. The PollSqsWorker (defined in bridge-base) calls this callback with the raw content of the SQS messages. This callback then deserializes the SQS message into a Bridge Exporter Request and calls the Record Processor.
Worker Manager
(worker) ExportSubtask - Corresponds to a single health data record in a Bridge-EX request. Contains references to the parent task, the schema, the raw DDB item, and the JSON representation of the health data (which might be different from the raw DDB item because of legacy surveys; see Legacy Hacks for details). These are immutable, so we reuse the same subtask if multiple handlers need to work on the same record.
(worker) ExportTask - The Worker Manager creates an ExportTask for each request. The Task references the request and stores the current task state, specifically TsvInfo for each study and each schema, the queue of outstanding asynchronous executions, and the set of studies we've seen so far. The Worker Manager and the Handlers refer to this object to track state. Also includes metrics and the task's temp dir on disk.
Note that this also includes the ExporterDate. This is exported to Synapse as UploadDate, but it is different from the UploadDate that comes from the health data record in DDB. The UploadDate in DDB tracks when the data was uploaded to Bridge. The ExporterDate (UploadDate in Synapse) tracks when the data was upload to Synapse. Since the Bridge Exporter runs every day at ~2am and pulls yesterday's data, these dates are (in normal circumstances) always different.
This was done because the ExporterDate and UploadDate were done for very similar but different use cases. The UploadDate in DDB is for the Bridge Exporter to keep track of which data set it needs to export to Synapse. The ExporterDate (UploadDate in Synapse) is for researchers to keep track of which data they have processed, and to determine "today's data drop".
(worker) ExportWorker - An asynchronous execution. The Worker Manager will create one for each record, and may make more than if the record needs, for example, both the Health Data handler and the AppVersion handler. This is executed in the Worker Manager's asynchronous thread pool and tracked in the ExportTask's asynchronous execution queue.
(worker) ExportWorkerManager - The main driver for the Exporter. This includes helper object instances and common helper functions to be used by handlers, as well as methods for task and handler management. ExportWorkerManager itself contains no state and offloads state to the ExportTask and its TsvInfo objects.
The Record Processor calls ExportWorkerManager for each health data record. ExportWorkerManager then creates a subtask and runs it against the AppVersion handler and the HealthData handler (and sometimes the IosSurvey handler; see Legacy Hacks), using ExportWorkers and the asynchronous thread pool to run these tasks asynchronously. We use a fixed thread pool with a configurable thread count to limit the number of concurrent asynchronous executions. Limiting the threads prevents resource starving, and excess tasks are queued up (with Java's built-in Executor handling queueing).
When the Record Processor is done iterating through all the records, it calls endOfStream(), signalling to ExportWorkerManager that there are no more subtasks. At this point, ExportWorkerManager blocks until all asynchronous executions in the current task's queue are complete (using the synchronous Future.get(); this can be thought of as the equivalent to fork-join). Once complete, it will signal to each HealthData and AppVersion handler to upload its payload to Synapse, then invoke the SynapseStatusTableHelper to update status tables.
(worker) TsvInfo - Every ExportTask contains a TsvInfo for each study AppVersion table and for each schema. The TsvInfo contains a reference to the TSV file on disk and a writer for that file. Given a mapping from column names to column values, it knows how to write that to the TSV. It keeps track of the column names so it can do this as well as line counts for metrics. The handlers will get the TsvInfo from from the ExportTask and call writeRow() with the column value map.
It is theoretically possible for two asynchronous executions to call the same handler with the same TsvInfo on two different records. In this case, it's unclear how the data will be written to the TSV. To prevent this, we synchronize writeRow().
Handlers
(handler) AppVersionExportHandler - This handler is for the poorly named AppVersion table. This table was originally meant to track AppVersions for each health data record. As the system evolved, this became the table used to track metadata for all records, used to compute stats and metrics, but the name stuck.
Every study has its own AppVersion handler. The Worker Manager calls this handler with a subtask, and the AppVersion handler will write the subtask's metadata to the AppVersion table, including a column for the original table, where the record's content lives. See the parent class SynapseExportHandler for more details.
(handler) ExportHandler - Abstract parent class for all handlers. The primary purpose for this class is to the ExportWorker (an asynchronous execution) can have a reference to a handler without needing to know what kind of handler it is. It also contains references to the Worker Manager and other various getters and setters concrete handlers need.
(handler) HealthDataExportHandler - Every schema has its own HealthData handler. The Worker Manager calls this handler with a subtask, and the HealthData handler will serialize the record's data into Synapse-compatible values (calling the SynapseHelper) and write those values to the Synapse table. This also includes logic to generate Synapse table column definitions based on a schema. See the parent class SynapseExportHandler for more details.
(handler) IosSurveyExportHandler - A special iOS Survey handler to support a legacy hack. See Legacy Hacks for more details.
(handler) SynapseExportHandler - This is the abstract parent class to both HealthData handler and AppVersion handler. This encapsulates logic to initialize the TsvInfo for a given task and schema, create the Synapse table if it doesn't already exist, column definitions and column values for common metadata columns, and upload the TSV to Synapse when the task is done.
Helpers
(dynamo) DynamoHelper - BridgeEX-specific DDB helper. Encapsulates querying, parsing, and caching for schemas, studies, and participant sharing scope. Also handles defaulting sharing scope to "no sharing" if the sharing scope could not be obtained from DDB.
(helper) ExportHelper - This helper contains some complex logic used for legacy hacks. See Legacy Hacks for more details.
(metrics) Metrics - Object for tracking metrics for a request, lives inside the ExportTask. CounterMap allows you to associate a count to a string. (Example: parkinson-TappingActivity-v6.lineCount = 73) KeyValuesMap allows you to associate one or more values to a given key. (Example: uniqueAppVersions[parkinson] = ["version 1.0.5, build 12", "version 1.2, build 31", "version 1.3-pre9, build 40"]). SetCounterMap allows you to associate a count to a string, but each count is associated with a value, which the counter dedupes on. (Example: uniqueHealthCodes[parkinson] = 49) All metrics use sorted data structures, so Bridge-EX can log the metric values in alphabetical order, for ease of log viewing.
Note that KeyValuesMap and SetCounterMap are both backed by a multimap. We keep them separate to make it clear that KeyValuesMap is used for the values while SetCounterMap is used for the count. The difference is because (a) KeyValuesMap is expected to have a small set of values while SetCounterMap is expected to have a large set of values (b) SetCounterMap counts unique health codes, which we don't want to write to our logs.
(metrics) MetricsHelper - Helper to encapsulate a few metrics-related functionality. This is used only by the Record Processor and exists mainly to keep the Record Processor from becoming too complicated. Current responsibilities include capturing metrics common to all records and writing all metrics to the logs at the end of a request.
(synapse) SynapseHelper - SynapseHelper, which includes simple wrappers around Synapse Java Client calls to include Retry annotations, as well as shared complex logic.
serializeToSynapseType() is used to convert raw health data records from JSON values in DDB to values that can be used in Synapse tables. If a value can't be serialized to the given type, it will return null. It also includes logic for downloading attachments from S3 and uploading them to Synapse as file handles. This is currently only used by HealthData handler.
uploadFromS3ToSynapseFileHandle() is a helper method to download an attachment from S3 and upload it to Synapse as a file handle. This also uses the Bridge type to determine the correct MIIME type for JSON and for CSVs, defaulting to application/octet-stream if the type is ambiguous. This is currently only used by SynapseHelper.serializeToSynapseType().
generateFilename() includes some clever logic to preserve file extensions (in case researchers actually care about file extensions), or insert a new file extension if the existing one doesn't make sense (for things like JSON or CSVs). This is currently only used by SynapseHelper.uploadFromS3ToSynapseFileHandle().
uploadTsvFileToTable() encapsulates multiple Synapse calls used to upload TSVs to a Synapse table, as well as a poll-and-wait loop to process the asynchronous call as a blocking call. This is used by SynapseExportHandler and its children.
createTableWithColumnsAndAcls() encapsulates logic to create a Synapse table with the given columns, principal ID (table owner), and data access team ID (permissions to view table). This is a common pattern found in all tables created by Bridge-EX. This is used by SynapseExportHandler and its children as well as the SynapseStatusTableHelper.
(synapse) SynapseStatusTableHelper - At the end of every request, the Worker Manager will invoke the SynapseStatusTableHelper to write a row to the status table of each study. This is intended for use by automated systems to determine when the Exporter has finished running for the night. Currently, the status row contains only today's date. The SynapseStatusTableHelper also creates the status table if it doesn't yet exist, offloading the logic to SynapseHelper.
(synapse) SynapseTableIterator - Currently defunct. This is an iterator to iterate through Synapse table rows individually. It used to be used by various helper scripts but is currently unused.
(util) BridgeExporterUtil - Static helper functions for Bridge-EX. Contains methods to build a schema key from a health data record DDB item and methods to extract values from DDB items and JSON objects and sanitize them (including stripping HTML, stripping newlines and tabs, and truncating strings to fit maximum length restrictions).
DynamoDB Tables
Exporter-Scheduler-Config - Contains configuration for Bridge-EX-Scheduler to call Bridge-EX. Lambda is unable to pass any parameters into Bridge-EX-Scheduler other than the function name, so we key off of function name and use this table to get Scheduler configs.
- schedulerName (hash key) - Matches the Lambda function name. Used to distinguish between devo, staging, and prod.
- sqsQueueUrl - SQS queue to write requests to
- timeZone - Currently configured to America/Los_Angeles (equivalent to Pacific Time) for all envs. In the future, if we need to launch Bridge-EX stacks in other regions, this may have other values.
- requestOverrideJson - Optional. Request template that the Bridge-EX-Scheduler uses and fills in "date" with yesterday's date. Generally used for specialized stacks with special parameters or for testing. Example:
{
"studyWhitelist":["api", "breastcancer", "parkinson"],
"sharingMode":"PUBLIC_ONLY"
}
(ddbPrefix)SynapseMetaTables - Bridge-EX automatically writes to this table to keep track of meta tables (specifically appVersion tables and status tables). The key is the table name, generally of the form "parkinson-appVersion" or "parkinson-status", and it maps to the Synapse table ID. Bridge-EX uses this table to remember if it's already created a table, and if so, where to find that table.
(ddbPrefix)SynapseTables - Similar to SynapseMetaTables, Bridge-EX automatically writes to this table to keep track of tables, in this case, health data tables. The key is the schema name, flattened into the form "parkinson-TappingActivity-v6", which also maps to Synapse table IDs.
Operations
Deployment
Bridge-EX
- Bridge-EX changes are committed to our GitHub repository (generally via pull requests): https://github.com/Sage-Bionetworks/Bridge-Exporter
- Travis (https://travis-ci.org/Sage-Bionetworks/Bridge-Exporter) automatically builds the latest commit and deploys it to AWS Elastic Beanstalk according to the Travis configuration (https://github.com/Sage-Bionetworks/Bridge-Exporter/blob/develop/.travis.yml)
- AWS Elastic Beanstalk automatically deploys the Bridge-EX code to the AWS-managed EC2 cluster (currently configured to be a "cluster" of one machine), and then automatically starts the service.
- To test, go to the SQS console and generate a sample request into the appropriate SQS queue.
- To deploy to staging (or prod), merge the code in GitHub from the develop branch to the uat branch (or from the uat branch to the prod branch). Using a local repository cloned from the root fork, run the following commands:
- git checkout develop
- git pull
- git checkout uat
- git merge --ff-only develop
- git push
Bridge-EX-Scheduler
- Make the Bridge-EX-Scheduler changes in your local repository and commit to the root in GibHub (generally via pull request): https://github.com/Sage-Bionetworks/Bridge-EX-Scheduler
- In your local repository, run "mvn verify", then upload target/Bridge-EX-Scheduler-2.0.jar to AWS Lambda using the AWS Lambda console.
- Unfortunately, Travis doesn't support automated deployments of Java to AWS Lambda, so we have to do it manually.
- To test, click the "Test" button in AWS Lambda.
Troubleshooting
Logs
NOTE: We're having data loss issues with Logentries. See Logentries support ticket (https://support.logentries.com/hc/en-us/requests/12415) and BRIDGE-1241 - Getting issue details... STATUS .
Logs can be found at https://logentries.com/. Credentials to the root Logentries account can be found at belltown:/work/platform/PasswordsAndCredentials/passwords.txt. Alternatively, get someone with account admin access to add your user account to Logentries.
If for some reason, the logs aren't showing up in Logentries, file a support ticket with Logentries. The alternative is to go to the AWS Elastic Beanstalk console, go to the environment you need logs for, go to Logs, and click on Request Logs. This will allow you to access the logs in your browser (if you choose Last 100 Lines) or download the logs to disk (if you choose Full Logs). The log file you're looking for is catalina.out.
If this doesn't work, you can try SSHing directly into the host.
- To find the hostname, go to a host tagged with the appropriate name (example, Bridge-EX-Prod), select it, and note the Public DNS in the description (example, ec2-52-91-223-70.compute-1.amazonaws.com).
- Download the security PEM from belltown:/work/platform/PasswordsAndCredentials/Bridge-EX-Prod.pem (or equivalent for another env).
- (This is optional, but makes things easier.) Set up your ~/.ssh/config with the following (replacing HostName and IdentityFile as needed). The host can be anything you want. User must be ec2-user.
host BridgeEX2-Prod
HostName ec2-52-91-223-70.compute-1.amazonaws.com
User ec2-user
IdentityFile ~/Bridge-EX-Prod.pem - SSH into the host. You may need to be in the Fred Hutch intranet or log into the Fred Hutch VPN.
- Logs can be found at /var/log/tomcat8/catalina.out
Metrics to Look For
When scrubbing the Bridge-EX logs the key metrics to look for are:
- number of ERRORs - Lots of errors generally means something is wrong at the systemic level. A single error generally means a record failed to upload to Synapse and is worth redriving or repairing. See Redrives for more info.
- The only ERROR worth ignoring is "Unable to parse sharing options for hash[healthCode]=-691460808, sharing scope value=null". However, if there are a lot of these, this generally indicates a systemic error
- On the flip side, exceptions and warnings generally aren't a problem. They generally are things like "#createFileHandleWithRetry(): attempt #1 of 5 failed", which indicates a Synapse call failed and was retried. That said, be sure to look at exceptions and warnings in case there are other problems.
- A log line that looks like "Finished processing request in 835 seconds, date=2016-03-16, tag=[scheduler=Bridge-EX-Scheduler-prod;date=2016-03-16]". This indicates that Bridge-EX completed successfully and how long it took. If this line is missing, it indicates that Bridge-EX never completed. If this request time is significantly higher, this indicates a systemic problem.
Below are other issues that are worth looking at, but are too cumbersome to look at manually. Rather, these are things we need to build an automated monitoring and alarm system for:
- accepted[ALL_QUALIFIED_RESEARCHERS], accepted[SPONSORS_AND_PARTNERS], excluded[NO_SHARING] - If there's a big shift in these numbers, it may indicate a bug in the Sharing Settings in Bridge, or possibly a major change in the app.
- parkinson-appVersion.lineCount (and similar for other studies) - These indicate the total number of entries exported to Synapse for a particular study. If this number shifts (up or down) by a lot, it may indicate a problems in the app or in Bridge.
- parkinson-TappingActivity-v6.lineCount (and similar for other studies and schemas) - Similarly, if any particular table sees large shifts, that could be a problem.
- *.errorCount - If this appear at all, that means there's an error. This generally doesn't suggest a systemic issue (unless the error count is high, in which case our logscan alarms would go off), but rather indicate that we need to redrive some records.
- numTotal - The total number of records Bridge-EX saw today across all studies and schemas, including records that were excluded or filtered out. Similarly, if this number shifts by a lot, it could be a problem.
- uniqueHealthCodes[parkinson] (and similar for other studies) - This represents the number of active users. If this drops suddenly, it indicates dataloss somewhere in the Bridge pipeline. If the number rises suddenly, it may not be an issue, but it's worth understanding the cause behind it.
Currently, we manually scrub our logs about once a week. We want to move this to an automated monitoring and alarming system. This may involve pumping the logs to CloudWatch (or another system) or writing a custom solution. It may involve sending the metrics in a different format so our monitoring solution doesn't need to parse raw logs.
See BRIDGE-1225 - Getting issue details... STATUS for tracking automated monitoring.
Monitoring and Alarms
We have logscan alarms in Logentries for 10+ ERRORs in an hour or for 100+ WARNs in an hour. These alarms send an email to bridgeit@sagebase.org.
We don't have a good automated monitoring system outside of logscans. See above or see BRIDGE-1225 - Getting issue details... STATUS for more details.