Synapse Replication & Migration of Database Objects
| version | comment |
|---|---|
| 2021/11/7 | Added this table |
| 2017/09/25 | Misc changes |
| 2014/01/07 | Added backfilling |
| 2013/06/03 | New migration method |
| 2012/08/02 | Created |
Introduction
Currently, Synapse is deployed and maintained with a Blue Green Deployment process. This means every week we create an entire staging stack of Synapse where we deploy all code and database changes. This staging stack is completely parallel to the production stack. When we are happy with all of the changes on the staging stack, we swap the URL and within minutes all clients are communicating with the new stack, making it the new production stack. This process is then repeated every week. In order, to make this process work we need to replicate all data from the production stack to the new staging stack. In fact, the data must be replicated semi-continuously to minimize our weekly down time. The rest of this document explains this replication process and how new objects participate in replication.
The following diagram shows the replication 'baseball diamond' of Synapse:
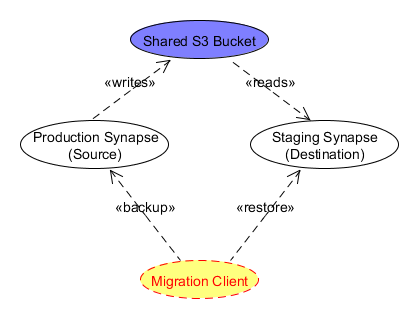
The production and staging Synapse do not directly communicate with each other. Rather the Migration Client (currently a command line tool run from Hudson), communicates with each stack and determines what needs to be replicated. When the client detects something is missing from the destination, or an etag in the source no longer matches the etag of the same object in the destination, it will request the source server to backup the object. This request will start a daemon worker that creates the requested backup zip file in S3. The migration client can monitor the daemon 's progress. When finished, the daemon status will includes the S3 URL of the backup file. The client can then pass this URL to the destination server as part of a restoration request. Again, a daemon worker will start to process this restore request and the client can monitor the progress. This process is repeated until all data is replicated from the source to destination.
Swapping URLs
The final step to promoting the staging stack to become production involves changing the public CNAMEs to point to the staging stack. Before this step can occur, we must ensure all data is replicated from the current production stack to the staging stack. This is done by putting the current production stack in read-only mode and starting one final pass of the migration client. If there are no errors and all of the counts match, the CNAMEs are swapped and stack that previously served as staging becomes production.
Extending Migration/Replication for new Objects
Prerequisites
Migration is currently based on each DBO (Database Object) each of which correspond to a single database table. All DBOs can be categories as either Primary or Secondary:
- Primary DBO - A primary DBO represents a database table that either is a parent to other tables or is a standalone table. These tables often represent the root of an object and will often have an etag column.
- Secondary DBO - A secondary DBO represents a database table that directly depends on another, primary table (or owner table). Any secondary table must have a foreign key to its owner table. (Note: A secondary or primary table may also have a foreign key constraint to a table in another database object. In this case the dependency must be reflected in the order of migration, as discussed in "Registering Migratable DBOs", below.)
Here is an example of both a Primary and Secondary DBO: Currently the NODE table is the root table for entities in Synapse. Since each Entity can have multiple versions, these version are represented in the REVISION table. In this example the NODE table is the Primary table and REVISION is secondary to NODE. The node table has an ID and an ETAG column, while the REVISION table has a foreign key to its OWNER_NODE.
This categorization is important because migration is currently driven off of Primary tables only. This means we detect changes in the primary tables across the two stacks. Whenever a change is detected in a primary table, a backup snapshot is made of the affected primary rows and all corresponding secondary table rows automatically. This means we do not need to keep track of changes to all tables, instead, we just ensure the ETag changes in the primary table whenever any change occurs at the primary or secondary levels.
The current backup and restoration process was designed to take full advantage of database batching. Previous versions of the migration client utilized slightly modified version of the same DAO (Database Access Object) code used to create, update, and delete objects at the API level. This resulted in at least one database call per row migrated. In several cases, migration of a single row involved multiple database calls as the normal DAO path was utilized. The single row approach was not scaling. The new migration process now migrates in batches of up to 25K rows.
Example
The following example shows the batch migration process of primary and secondary tables. Assume we have the following two tables.
WIKI
| ID | NAME | etag |
|---|---|---|
| 1 | foo | uu4 |
| 2 | bar | uu7 |
| 3 | everything | uu9 |
WIKI_ATTACHMENT
| ID | WIKI_OWNER_ID |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 3 |
| 4 | 3 |
In this example, WIKI is a primary table that tracks each wiki page. The WIKI_ATTACHMENT table is a secondary table that tracks all of the attachments associated with each wiki, where WIKI_OWNER_ID is a foreign key to WIKI ID. Now assume we have detected that wiki "1"'s etag differs between the source and destination, and wiki "3" is missing from the destination. For this case, the migration client would request that the sources server create a backup of one and three. If we were to look at the resulting zipped XML backup file in S3 it would look something like this:
<WIKI_LIST>
<WIKI>
<ID>1</ID>
<NAME>foo</NAME>
<ETAG>uu4</ETAG>
</WIKI>
<WIKI>
<ID>3</ID>
<NAME>everything</NAME>
<ETAG>uu9</ETAG>
</WIKI>
</WIKI_LIST>
<WIKI_ATTACHMENT_LIST>
<WIKI_ATTACHMENT>
<ID>1</ID>
<WIKI_OWNER_ID>1</WIKI_OWNER_ID>
</WIKI_ATTACHMENT>
<WIKI_ATTACHMENT>
<ID>2</ID>
<WIKI_OWNER_ID>1</WIKI_OWNER_ID>
</WIKI_ATTACHMENT>
<WIKI_ATTACHMENT>
<ID>3</ID>
<WIKI_OWNER_ID>3</WIKI_OWNER_ID>
</WIKI_ATTACHMENT>
<WIKI_ATTACHMENT>
<ID>4</ID>
<WIKI_OWNER_ID>3</WIKI_OWNER_ID>
</WIKI_ATTACHMENT>
</WIKI_ATTACHMENT_LIST>
The client would then tell the destination stack to restore the above file from S3.
The destination server would then perform the following database operations:
- A single batch “INSERT … ON DUPLICATE KEY UPDATE” for the entire <WIKI_LIST>
- Delete all rows from WIKI_ATTACHMENT where WIKI_OWNER_ID in (1,3)
- A single batch INSERT for the entire <WIKI_ATTACHMENT_LIST>
For real example, the batches could contain up to 25 K rows for the primary and as many rows as needed for the secondary table, so +50 K rows can be created/updated with three database calls.
Configuration
To enable the above migration process for existing table and new tables, we need to tell the migration-sub-system about our tables. Most of this configuration is achieved by implementing the org.sagebionetworks.repo.model.dbo.MigratableDatabaseObject interfaces with your DBO.
The MigratableDatabaseObject<D, B> interfaces has two generic parameters D and B. The D parameters will always be the DBO class itself, while the second parameter B can be any POJO (Plain Old Java Object) that represents a backup object. The backup class will become important when you want to change the schema of your table in the future. When you first create a new DBO feel free to use the DBO as the backup object. You can change it when/if there is a schema change in the future.
The MigratableDatabaseObject interface is a contract with 5 methods:
| return | method | description |
|---|---|---|
| MigrationType | getMigratableTableType() | Extend the MigrationType enumeration for you new type and return the type here. The order of this enumeration is important and will control the order of migration. If a new object depends on another DBO (i.e. foreign key to another table), then the new type should come after the dependency. Cycles are not allowed. |
| MigratableTableTranslation<D,B> | getTranslator() | The translator is a simple translation from a DBO to a backup object and a backup object to a DBO. The translator will handle any schema changes within a single table. When a new DBO is created, the translator can simply return the passed object for both createDatabaseObjectFromBackup() and createBackupFromDatabaseObject(). More sophisticated translation can be added later, as needed, to support schema changes. |
| Class<? extends B> | getBackupClass() | The class of your backup object |
| Class<? extends D> | getDatabaseObjectClass() | The class of the database object. |
| List<MigratableDatabaseObject> | getSecondaryTypes() | If this object is the 'owner' of other object, then it is a primary type. All secondary types should be returned in their migration order. For example, if A owns B and B owns C (A->B->C) then A is the primary, and both B and C are secondary. For this case, return B followed by C. Both B and C must have a backup ID column that is a foreign key to the backup ID of A, as the IDs of A will drive the migration of B and C. |
Identifying Important Columns
Notice that MigratableDatabaseObject extends DatabaseObject<D>. The DatabaseObject<D> interface is a basic interfaces where the fields of a DBO are mapped to a database table. This is done by providing a list of FieldColumn for this mapping. The FieldColumn object has been extended for migratable database objects. There are three important Booleans in FieldColumn that are used to identify columns that drive migration:
| name | Description |
|---|---|
| isEtag | Any mutable primary table must have an Etag column that is used by the migration process to detect changes across the source and destination stacks. Etag columns must be created with a NOT NULL constraint. Immutable tables do not need etags. |
| isBackupId | Used to indicate the column that is the backup ID. The backup ID must map to a Java Long. For primary tables, the backup ID must be unique within the primary table. For secondary tables the backup ID must map to the foreign key column that references the primary table backup ID. For most primary tables, the backup ID simply maps to the primary key of the table. For any primary table that has a primary key that spans multiple columns a separate backup ID column must be added. The backup ID is the glue that ties primary tables to their secondary tables. |
| isSelfForeignKey | For any primary table that has a column that is a foreign key another column on the same table, the column with the foreign key constraint must be identified with this flag. For example Node has a column called PARENT_ID that is a foreign key to the ID column of the Node table. In this example, the PARENT_ID column is set to isSelfForeignKey=true. Setting this flag ensures that parent rows are created before their dependent children rows. |
Registering Migratable DBOs
Once the DBO implements MigratableDatabaseObject it can be registered with the MigatableTableDAOImpl.
NOTE: Only the primary types are registered with the MigatableTableDAOImpl. Secondary types are automatically discovered via the MigratableDatabaseObject.getSecondaryTypes() method on primary types.
The MigratableDatabaseObject are registered by adding an entry to the Synapse-Repository-Services\lib\jdomodels\src\main\resources\dbo-beans.spb.xml file. The order of this list of beans is important and determines the order all primary types are migrated relative to each other. An new primary type should be listed after any table it depends and before any table that depends on it. Cycles are not allowed.
Here is what the bean looked like at the time of this post:
<bean id="migatableTableDAO" class="org.sagebionetworks.repo.model.dbo.migration.MigatableTableDAOImpl" init-method="initialize">
<property name="maxAllowedPacketBytes" ref="stackConfiguration.migrationMaxAllowedPacketBytes"/>
<property name="databaseObjectRegister">
<list>
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOUserGroup" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOUserProfile" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOFileHandle" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOWikiPage" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOWikiOwner" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOActivity" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBONode" />
<bean class="org.sagebionetworks.evaluation.dbo.EvaluationDBO" />
<bean class="org.sagebionetworks.evaluation.dbo.ParticipantDBO" />
<bean class="org.sagebionetworks.evaluation.dbo.SubmissionDBO" />
<bean class="org.sagebionetworks.evaluation.dbo.SubmissionStatusDBO" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOAccessRequirement" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOAccessApproval" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOFavorite" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOTrashedEntity" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBODoi" />
<bean class="org.sagebionetworks.repo.model.dbo.persistence.DBOChange" />
</list>
</property>
</bean>
Moving from One Table to Another
A MigratableTableTranslation implementation provides all of the hooks needed to add and remove columns from a single table. It can also be used to merge and split columns of a single table. However, it is not possible to use a translator to move data from one table to another.
Whenever, data needs to be refactored out of one table into another there are two separate operations that we recommend implementing:
- Data Mirroring - This means changing the code such that the data is "mirrored" to both the old and new table for all create, update, and delete operations. While data is being mirrored, the original table should be treated as the "truth".
- Data Back-filling - Mirroring works great for all data that is modified, but what about all of the existing data in the old table. A mechanism is need to "back-fill" the new table with the old data.
The following example shows the workflow for moving data from one table to another over the course of two separate stacks.
Assume we want to move data from table FOO to table BAR and we are currently on stack 101. To move this data without data loss we can first setup a "mirror" and "back-filling" on stack 102. For the life of stack 102, the FOO table will remain the "truth" for the data that is being moved. While stack 102 is on staging we can continue to validate that both the data mirroring and back-filling is working as expected and no data is lost. If all goes well the BAR table should have all of the data needed from the FOO table.
Next, on stack 103, both the back-filling and data mirror are removed, and code is refactored to use the BAR table as the "truth".
The following summarizes where data changes can occur and how the change is replicated from FOO to BAR:
- CRUD operations on stack 101 will affect the FOO table. Since there is no mirroring on 101, the back-filling tied to migration on 102 will capture all of these changes.
- CRUD operations on stack 102 will mirror both to FOO and to BAR. Then subsequent migrations (from 101 to 102) will "undo" all changes on 102.
- CRUD operations on stack 103 will be written exclusively to BAR. The normal migration process will keep BAR in synch between 102 and 103.
Data Mirroring
Data mirror can be done separately from migration. The manager or DAO level code can simply be modified to "mirror" the data from original table to the new table with all create, update, and delete operations. There is no special coordination needed with the migration process for mirroring.
Data Back-filling
Unlike, the data mirroring, the back-filling process needs to be coordinated with migration process. In the above example, while stack 101 was in production, any changes to the FOO table would be migrated to FOO on 102. A simple way to implement back-filling from FOO to BAR is to "listen" to the migration of FOO events on stack 102. In other words, when 102 is told to create, update, or delete rows from FOO by the migration process, a "listener" bean to this process also performs the corresponding operation on BAR.
To listen to migration events, first create a bean that implements org.sagebionetworks.repo.manager.migration.MigrationTypeListener and register it with the migration manager. Here is an example of a modification made to the managers-spb.xml file:
<bean id="migrationManager" class="org.sagebionetworks.repo.manager.migration.MigrationManagerImpl" scope="singleton">
<property name="backupBatchMax"
ref="stackConfiguration.migrationBackupBatchMax" />
<property name="migrationListeners">
<list>
<bean class="org.sagebionetworks.repo.manager.migration.PrincipalMigrationListenerImpl"/>
</list>
</property>
</bean>
In the above example, a Spring bean is registered with the MigrationManager. This allows the PrincipalMigrationListenerImpl to "listen" to all migration events. In this example, when USERGROUP changes occurred, the "name" was copied to the PRINCIPAL_ALIAS table. This allowed us to move the "name" field from one table to another.
Note: The order of the MigrationManager.migrationListeners list will be respected, and each listener is called in order.
NOTE: When a registered listener is called, it's only guaranteed that the contents of the PRIMARY migration table have been written to the target database. Any SECONDARY data will not yet be written at the time that the listener is invoked.
NOTE: Migration listeners should not change the ETAG of any table, since doing so will cause the migration process to register discrepancies between production and staging. For example, calling at DAO-level method to update an object will likely make such an erroneous ETAG change.
Testing
There is a single test that simulates the entire migration process for all objects: Synapse-Repository-Services\services\repository\src\test\java\org\sagebionetworks\repo\web\migration\MigrationIntegrationAutowireTest.java
Whenever a new migratable type is created, this test must be extended to create at least one instance of the the type. The test will then automatically, backup, delete, then restore, the new instance.
Turning an immutable table into a mutable one
In order to turn an immutable table into a mutable one, the following steps should be taken:
- Add an etag column with a NOT NULL constraint to the table.
- In the createDatabaseObjectFromBackup() method of the DBO's translator, set a default etag when the backup's etag is null.
- Make sure not to mutate the table in staging or deploy any services that mutate the table in staging until the new etag column is live in production. This is important to make sure that unwanted changes made in staging don't make it to production. While the new etag column is in staging but not in production, changes made in staging will not be undone. This is due to the fact that migration skips source rows that don't have an etag column.