Data Sources
At the highest level, the Synapse REST API is supported from a single war file deployed to Amazon's Elastic Beanstalk call the repository.war. While the repository services reads data from many sources including RDS (MySQL), S3, CloudSearch, Dynamo, SQS, it will only write to RDS and S3.
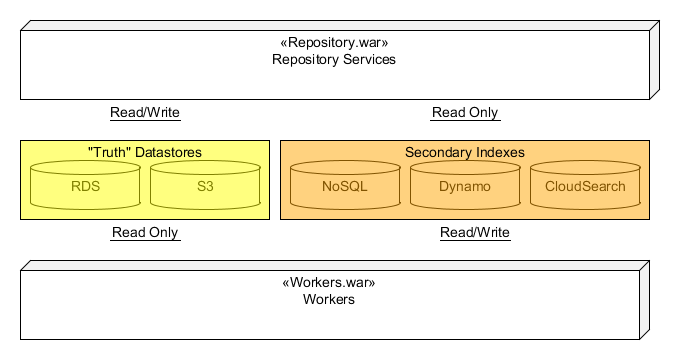
Any REST call that writes data will always be in a single database transaction. This includes writes where data is stored in S3. For such cases, data is first written to S3 using a key containing a UUID. The key is then stored in RDS as part of the single transaction. This means any S3 data or RDS data will always have read/write consistency. All other data sources will be eventual consistent.
Asynchronous processing
As mentioned above, the repository services only writes to RDS and S3. All other data-sources (Dynamo, CloudSearch, etc.) are secondary and serve as indexes for quick data retrieval for things such as ad hock queries and search. These secondary indexes are populated by a secondary application called "workers". The details of these worker will be covered more detail later, but for now, think of the workers as a suite of processes that respond to messages generated by the repository services.
Message generation
Anytime data is written to Synapse through the repository services, a message is generated and sent to an Amazon SNS Topic. The topic acts as a message syndication system, that pushes a copy of the message to all Amazon SQS queues that are registered with the topic. Each worker process watches is "own" queue. The following sequence diagram shows how the repository service generates a message in response to a write:
![]()
In the Above example, a create entity call is made, resulting in the start of a database transaction. The entity is then inserted into RDS. A change message containing meta data about this new entity (including ID and Etag) is also inserted into RDS as part of this initial transaction to the changes table. The change message object is also bound to the transaction in an in-memory queue. When this initial transaction is committed, a transaction listener is notified, and all messages bound to that transaction are sent to an SNS Topic.
Message Generation Fail-safe
Under adverse conditions it is possible that an RDS write is committed, yet a message is not sent to the topic. For example, the repository services instance is shut down after a commit but before the messages can be sent to the topic. A special worker is used to detect and recover from such failures. This worker scans for deltas between the changes table and the sent message table. Anytime a discrepancy is found, the worker will attempt to re-send the failed message(s). This worker also plays in important roll in stack migration which will be covered in more detail in a later section.
Message Guarantees:
- A Change Message is recorded with the original transaction, if the write is committed then, so is the record of the change in the change table.
- Messages are not published until after the transaction commits, so race conditions on message processing is not possible.
- Under normal condition messages are sent immediately.
- A system is in place to detect and re-send any failed messages.
Message processing
While the workers application is deployed to Elastic Beanstalk in the works.war, it does not actually handle any web requests (other than administration support). Instead we are utilizing the "elastic" properties of Beanstalk, to manage a cluster of workers. This includes automatically scaling up and down, multi-zone deployment and failure recovery. The workers application consists of a suite of Spring Beans that are each run on their own timer as part of a larger Quartz scheduler. Each worker timer is gated by a RDS backed semaphore that limit the number of current workers of each type that can be run across the cluster. This allows the work to be more evenly distributed across the cluster.
Each worker in the suite has its own Amazon SQS queue that is