| date | comment |
|---|---|
| 202109 | reviewed - no change |
| Table of Contents |
|---|
Data Sources
At the highest level, the Synapse REST API is supported from a single two separate war file files deployed to Amazon's Elastic Beanstalk call . The first war provides all web-services for the REST API and is called the repository.war. While the repository services reads data from many sources including RDS (MySQL), S3, CloudSearch, Dynamo, SQS, it will only write to RDS and S3.The second war builds all secondary index data used by repository services and is called the worker.war. All "truth" data of Synapse resides in RDS and S3. This truth data is written directly from the repository when a Create, Update, or Delete web-services is called. After writing the truth data to RDS or S3, the repository service will broadcast a change message to an Amazon SNS Topic. A worker from the workers.war will then pickup the change massages and update one or more of the secondary indexes. The relationship is shown in the following diagram:
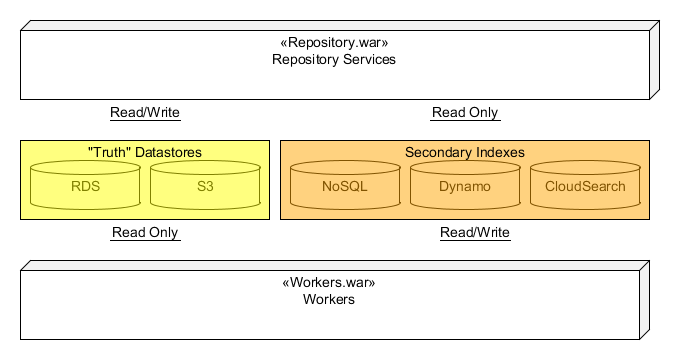
Any REST call that writes data from the repository services will always be in a single database transaction. This includes writes where data is stored in S3. For such cases, data is first written to S3 using a key containing a UUID. The key is then stored in RDS as part of the single transaction. This means any S3 data or RDS data will always have read/write consistency (although there may be "orphaned" files in S3 if a transaction fails). All other secondary data sources will be eventual are eventually consistent.
Although there are many logically independent web services in Synapse, they are all bundled in a single .war for deployment to a single Elastic Beanstalk environment, which provides autoscalling for all the services at minimal cost given the moderate traffic on Synapse. The workers.war is deployed to a second Elastic Beanstalk environment, ensuring that worker processes can not interfere with the performance of the webservices tier. Again, several logically independent workers are bundled into one deployable unit, again for reasons of cost and opperational simplicity.
Asynchronous processing
As mentioned above, the repository services only writes to RDS and S3. All other data-sources (Dynamo, CloudSearch, etc.) are secondary and serve as indexes for quick data retrieval for things such as ad hock queries and search. These secondary indexes are populated by a secondary application called "workers"the workers in the workers.war. The details of these worker will be covered more detail later, but for now, think of the workers as a suite of processes that respond to messages generated by the repository services.
...
The resilience of these works is provided by a combination of the features of Amazon's SQS, Elastic Beanstalk, and Quartz.
Repository Layers
Each repository services is composed of at least four distinct layers:
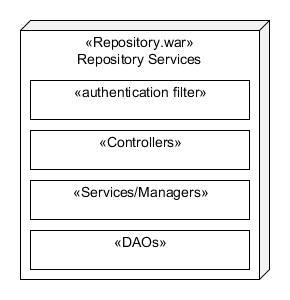
Authentication Filter
The Authentication filter is a servlet filter that is applied to most repository service URLs. The filters only function is to authenticate the caller. There are several mechanism with which a user may authenticate including a Session Token added to the header of the request or signing the request using their API key. For more information about authentication see: Authentication Controller. Once the filter authenticates a user, the user's ID is passed along with the request.
Controllers
The controller's layer simply maps all of the components of an HTTP request into a Java method call. This includes the URL path, query parameters, request and response body marshaling, error handling and other response codes. Each controller also groups calls in the same category into a single file. The javadocs of each controller also serves as the source for the REST API documentation auto-generation. Each controller is a very thin layer that depends on the service layer.
All request and response bodies for the repository services have a JSON format. The controller layer is where all Plain Old Java Objects (POJOs) are marshaled to/from JSON. Every request and response objects is defined by a JSON schema, which is then used to auto-generate a POJO. For more information on this process see the /wiki/spaces/JSTP/pages/7867487 and the /wiki/spaces/JSTP/overview project.
Services/Manager
Ideally the services/managers layer encapsulates all repository services "business logic". This business logic includes any object composition/decomposition. This layer is also where all authorization rules are applied. If the caller is not allowed to perform some action an UnauthorizedException will be raised. Managers interact with datastore such a RDS using a DAO, which will be covered in more details in the next section.
DAO
A Data Access Object (DAO) serves as an abstraction to a datastore. For example, WikiPages are stored in a RDS MySQL database. The WikiPageDAO serves an an abstraction for all calls to the database. This forces the separation of the "business logic" from the details of Creating, Reading, Updating, and Deleteing (CRUD) objects from a datastore.
One of the major jobs of a DAO is the translation between Data Transfer Objects (DTO) which are the same objects exposed in the public API, to Database Objects (DBO). This translation means DTOs and DBOs can be loosely coupled. So a database schema change might not result in an API change and vice versa. This also provides the means to both normalize and de-normalize relational database data. For example, an WikiPage (a DTO) object provided by an API caller will be translated into four normalized relational database tables each with a corresponding DBO.
Acronym summary:
- DTO - Data Transfer Object is same object end-users see/use when making API calls.
- DBO - Database Object is a POJO that maps directly to table. For every column of the table there will be a matching field in the corresponding DBO. See Adding New Database Objects
- DAO - Data Access Object is the abstraction that translates to DTOs into DBOs directly performs all datasource CRUD.
- CRUD - Create, Read, Update, and Delete.
Workers
The workers war is composed of many workers each performing separate tasks. The following diagram shows the components of a typical worker using "search" as an example:
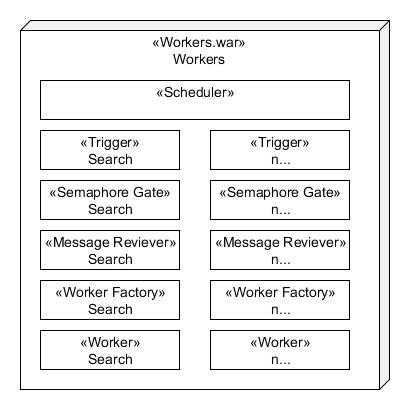
Scheduler
All of the works are controlled by a shared Quartz scheduler that controls the thread pool used to run each worker.
Trigger
Each worker defines its own trigger that controls the frequency which the workers runs.
Semaphore Gate
The SemaphoreGatedRunner is a re-usable class that each worker can use to control cluster wide concurrency of that worker. Each instance of the SemaphoreGatedRuner is configured for a single worker type. The worker is assigned a unique key string that is used as lock, the maximum number of concurrent worker instances that can be run across the entire worker cluster, and a timeout. A Runner is also provided (IoC) to "run" while the lock is being held.
When the scheduler fires according to the trigger, the SemaphoreGatedRunner's execute methods is called. The semaphore will generate a random number between 0 and the maximum number of workers of that type (exclusive) and concatenate that number with the worker's unique key to generate a lock string. It will then attempt to acquire a global lock on that string using the semaphore RDS table. If a lock is acquired, it will be held in a try/finally block while configured runner is executed. It will unconditionally release the lock when the Runner's run() method returns.
Locking Guarantees:
- When lock is issued, it is guaranteed to be held until released by the lock holder or the configured timeout is exceeded.
- The same lock will not be issued to multiple callers.
- Lock acquisition is non-blocking, meaning it does not wait for a lock to be acquire. In other words, the SemaphoreGatedRunner will return to the caller immediately if a lock cannot be acquired.
- When a lock is acquired a new unique token is issued to the lock holder. This token must be used to release the lock. The means if one thread is issued a lock but does not release it before the configured timeout is exceed, then the same lock can be issued to another thread but with a new token. Since the original thread's token is no longer bound to the lock, that token cannot be used to release the lock since it had been re-issued to the other caller.
Message Receiver
The message receiver is a re-usable class that is configured to pull message from an AWS SQS queue. Each instance is configured with a WorkerFactory (IoC) that is used to create workers that process messages from the queue. When a worker successfully consumes a massage it is return it to the MessageReceiver which will then delete the message from the queue.
Massage Fail-safes
Most of the message fail-safes are provided by SQS.
- A message is guaranteed to be issued to one an only one caller at a time.
- Once a message is issued it become "invisible" until it is either deleted (or "consumed") or the visibility timeout is exceeded.
- If a message is not deleted before its visibility timeout is exceed the message might be re-issued to another caller.
- Messages can only remain in the queue for a limited period of time (typically 4 days), so failed messages are eventually flushed from the queue.
A Worker
When the timer fires, a lock is acquired, and there is a message to be process a new worker instances will be generated to "consume" the message. It is the job of the worker to do actual work with a message. When the worker processes the message successful, it returns the message to the MessageReciever, which will then delete the message from the queue. When an error occurs it is the job of the worker to determine which type of error occurred. There are two types of errors:
- Recoverable errors. For example if there is a communication error, then as soon communication is restored the message can be processed successfully.
- Non-recoverable errors - For example the message is malformed. Such message will never be processable.
Important: All messages associated with non-recoverable errors should be returns to the message receiver so they can be deleted from the queue. If they are not deleted, they will build up in the queue and slow down all processing for the worker.
Recoverable errors should not be returned to the the MessageReciever so they will remain on the queue where they can be re-processed later.