Note that we went with pre-signed urls and plan to switch to IAM tokens instead of IAM users when that feature is launched.
Dataset Hosting Design
| Table of Contents |
|---|
Assumptions
Where
Assume that the initial cloud we target is AWS but we plan to support additional clouds in the future.
For the near term we are using AWS as our external hosting partner. They have agreed to support our efforts for CTCAP. Over time we anticipate adding additional external hosting partners such as Google and Microsoft. We imagine that different scientists and/or institutions will want to take advantage of different clouds.
We can also imagine that the platform should hold locations of files in internal hosting systems, even though not all users of the platform would have access to files in those locations.
Metadata references to hosted data files should be modelled as a collection of Locations, where a Location could be of many types:
- an S3 URL
- a Google Storage URL
- an Azure Blobstore URL
- an EBS snapshot id
- a filepath on a Sage internal server
- ....
| Code Block |
|---|
Class Location
String provider // AWS, Google, Azure, Sage cluster – people will want to set a preferred cloud to work in
String type // filepath, download url, S3 url, EBS snapshot name
String location // the actual uri or path
|
What
For now we are assuming that we are dealing with files. Later on we can also envision providing access to data stored in a database and/or a data warehouse.
We also assume that this data can be stored in S3 in plain text (no encryption).
We also assume that only "unrestricted" and "embargoed" data are hosted by Sage. We assume that "restricted" data is hosted elsewhere such as dbGaP.
Who
Assume tens of thousands of users will eventually use the platform.
How
Assume that users who only want to download do not need to have an AWS account.
Assume that anyone wanting to interact with data on EC2 or Elastic MapReduce will have an AWS account and will be willing to give us their account number (which is a safe piece of info to give out, it is not an AWS credential).
Design Considerations
- metadata
- how to ensure we have metadata for all stuff in the cloud
- file formats
- tar archives or individual files on S3?
- EBS block devices per dataset?
- file layout
- how to organize what we have
- how can we enforce a clean layout for files and EBS volumes?
- how to keep track of what we have
- access patterns
- we want to make the right thing be the easy thing - make it easy to do computation in the cloud
- file download will be supported but will not be the recommended use case
- recommendations and examples from the R prompt for interacting with the data when working on EC2
- security
- not all data is public
- encryption or clear text?
- key management
- one time urls?
- intrusion detection
- how to manage ACLs and bucket policies
- are there scalability upper bounds on ACLs? e.g., can't add more than X AWS accounts to an ACL
- auditability
- how to have audit logs
- how to download them and make use of them
- human data and regulations
- what recommendations do we make to people getting some data from Sage and some data from dbGaP and co-mingling that data in the cloud
- monitoring - what should be monitored
- access patterns
- who
- when
- what
- how much
- data foot print
- upload bandwidth
- download bandwidth
- archive to cheaper storage unused stuff
- cost
- read vs. write
- cost of allowing writes
- cost of keeping same data in multiple formats
- can we take advantage of the free hosting for http://aws.amazon.com/datasets even though we want to keep an audit log?
- how to meter and bill customers for usage
- operations
- how to make it efficient to manage
- reduce the burden of administrative tasks
- how to enable multiple administrators
- how long does it take to get files up/down?
- upload speeds - we are on the lambda rail
- shipping hard drives
- durability
- data corruption
- data loss
- scalability
- if possible, we want to only be the access grantors and then let the hosting provider take care of enforcing access controls and vending data
High Level Use Cases
Users want to:
- download an unrestricted dataset
- download an embargoed dataset for which the platform has granted them access
- use an unrestricted dataset on EC2
- use an embargoed dataset for which the platform has granted them access on EC2
- use an unrestricted dataset on Elastic MapReduce
- use an embargoed dataset for which the platform has granted them access on Elastic MapReduce
There is a more exhaustive list of stuff to consider above but what follows are some firm and some loose requirements:
- enforce access restrictions on datasets
- log downloads
- log EC2/EMR usage
- figure out how to monitor user usage such that we could potentially charge them for usage
- think about how to minimize costs
- think about how to ensure that users sign a EULA before getting access to data
Options to Consider
AWS Public Data Sets
Scenario:
- Sage currently has two data sets stored as "AWS Public Datasets" in the US West Region.
- Users can discover them by browsing public datasets on http://aws.amazon.com/datasets/Biology?browse=1 and also via the platform.
- Users can use them for cloud computation by spinning up EC2 instances and mounting the data as EBS volumes.
- Users cannot directly download data from these public datasets, but once the have them mounted on an EC2 host, they can certainly
scpthem to their local system. - Users cannot directly use these files with Elastic Map Reduce. Instead they would need to first upload them to their own S3 bucket.
- Users are not forced to sign a Sage-specified EULA prior to access since because they can bypass the platform directly and access this data via normal AWS mechanisms.
- Users must have an AWS account to access this data.
- There is no mechanism to grant access. All users with AWS accounts are granted access by default.
- There is no mechanism to keep an audit log for downloads or other usage of this data.
- Users pay for access by paying their own costs for EC2 and bandwidth charges if they choose to download the data out of AWS.
- The cost of hosting is free.
Future Considerations:
- this is currently EBS only but it will also be available for S3 in the future
- TODO ask Deepak what other plans they have in mind for the re-launch of AWS Public Datasets.
- TODO tell Deepak our suggested features for AWS Public Datasets.
Tech Details:
- You create a new "Public Dataset" by
- making an EBS snapshot in each region in which you would like it to be available
- providing the snapshot id(s) and metadata to Deepak (TODO see if this is still the case)
- then you wait for Amazon to get around to it
Pros:
- free hosting!
- scalable
Cons:
- this won't work for public data if it is a requirement that
- all users provide an email address and agree to a EULA prior to access
- we must log downloads
- this won't work for protected data unless the future implementation provides more support
Custom Proxy
All files are kept completely private on S3 and we write a custom proxy that allows users with permission to download files whether to locations outside AWS or to EC2 hosts.
Scenario:
- See details below about the general S3 scenario.
- This would not be compatible with Elastic MapReduce. Users would have to download files to an EC2 host and then store them in their own bucket in S3.
- The platform grants access to the data by facilitating the proxy of their request to S3.
- Users do not need AWS accounts.
- The platform has a custom solution for collecting payment from users to pay for outbound bandwidth when downloading outside the cloud.
Tech Details:
- We would have a fleet of proxy servers running on EC2 hosts that authenticate and authorize users and then proxy download from S3.
- We would need to configure auto-scaling so that capacity for this proxy fleet can grow and shrink as needed.
- We would log events when data access is granted and when data is accessed.
Pros:
- full flexibility
- we can accurately track who has downloaded what when
Cons:
- we have another service fleet to administer
- we are now the scalability bottleneck
S3
Skipping a description of public data on S3 because the scenario is very straightforward - if get the URL you can download the resource. For example: http://s3.amazonaws.com/nicole.deflaux/ElasticMapReduceFun/mapper.R
Unrestricted and Embargoed Data Scenario:
- All Sage data is stored on S3 and is not public.
- Users can only discover what data is available via the platform.
- Users can use the data for cloud computation by spinning up EC2 instances and downloading the files from S3 to the hard drive of their EC2 instance.
- Users can download the data from S3 to their local system.
- The platform directs users to sign a Sage-specified EULA prior to gaining access to these files in S3.
- Users must have a Sage platform account to access this data for download. They may need an AWS account depending upon the mechanism we use to grant access.
- The platform grants access to this data. See below for details about the various ways we might do this.
- The platform will write to the audit log each time it grants access. S3
can also be configured to log all access to resources and this could serve
as a means of records for billing purposes and also intrusion detection.- These two types of logs will have log entries about different events (granting access vs. using access) so they will not have a strict 1-to-1 mapping between entries but should have a substantial overlap.
- The platform can store anything it likes in its audit log.
- The S3 log stores normal web access log type data with the following identifiable fields:
- client IP address is available in the log
- "anonymous" or the user's AWS canonical user id will appear in the log
- We can leave these logs on S3 and run Elastic MapReduce jobs on them
when we need to do data mining. Or we can download them and do data mining locally.
- See proposals below regarding how users might pay for outbound bandwidth.
- The cost of hosting not free.
- Storage fees will apply.
- Data import fees:
- Bandwidth fees apply when data is uploaded.
- Data can also be shipped via hard drives and AWS Import/Export fees would
apply.
- Data export fees:
- Bandwidth fees apply when data is downloaded out of AWS. There is no charge when it is downloaded inside AWS (e.g., to an EC2 instance).
- Data can also be shipped via hard drives and AWS Import/Export fees would
apply.
- These same fees apply to any S3 log data we keep on S3.
Resources:
...
Proposal
- All data is stored on S3 as our hosting partner.
- All data will be served over SSL/HTTPS.
- We will have one Identity and Access Management (IAM) group for read-only access all datasets.
- We will generate and store IAM credentials for each user that signs any EULA for any dataset. The user will be added to the read-only access IAM group.
- We never give those IAM credentials out, we only use them to generate pre-signed S3 URLs with an expiry time of an hour or so.
- With these pre-signed URLs, users are able to download data directly from S3 using the Web UI, the R client, or even something simple like curl.
- Our Crowd groups are more granular and tell which which users are allowed to have pre-signed URLs for which datasets.
- The use of IAM allows us to merely track in the S3 access logs who has downloaded what.
- Users can download this files to EC2 hosts (no bandwidth charges for Sage) or to external locations (Sage pays bandwidth charges).
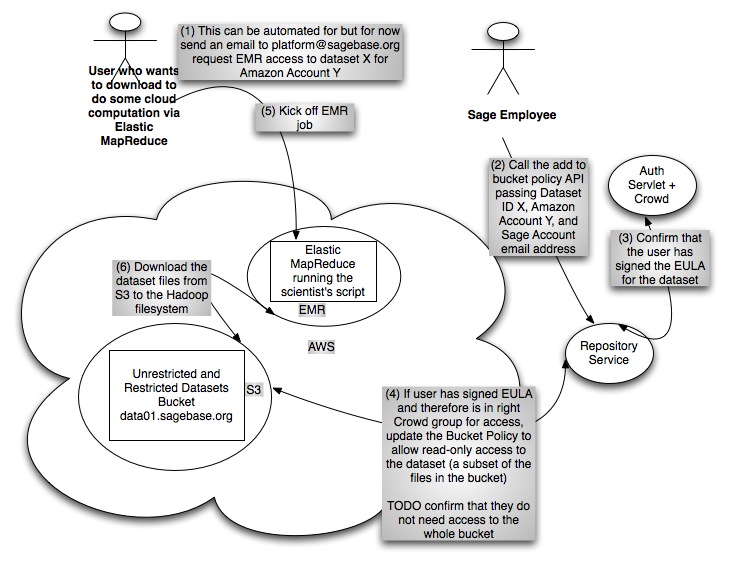
- For users who want to utilize Elastic MapReduce, which does not currently support IAM, we will add them to the Bucket Policy for the dataset bucket with read-only access.
Sage Employee Use Case
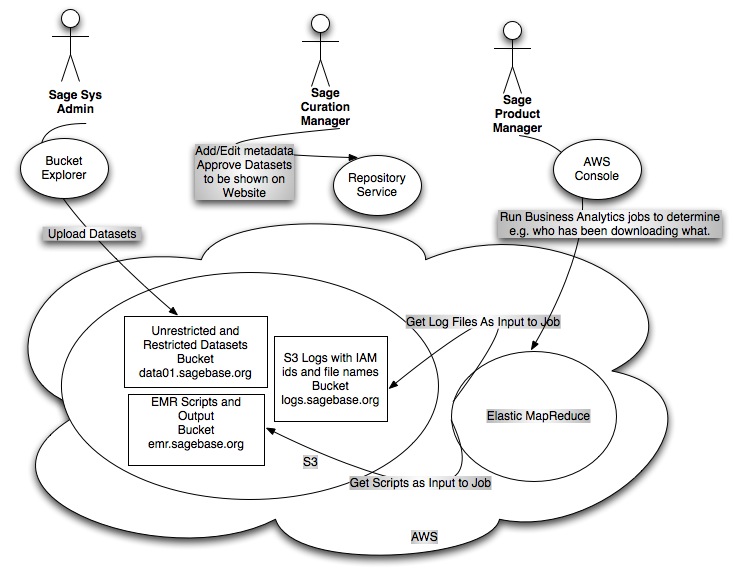
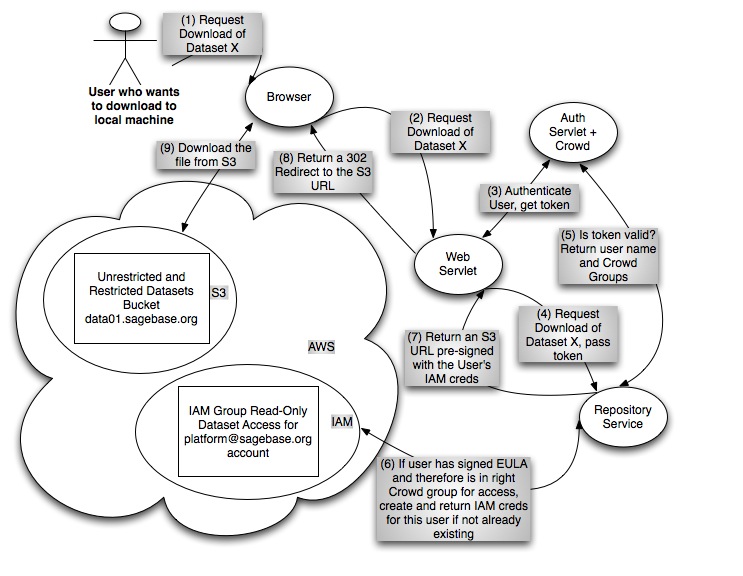
Download Use Case
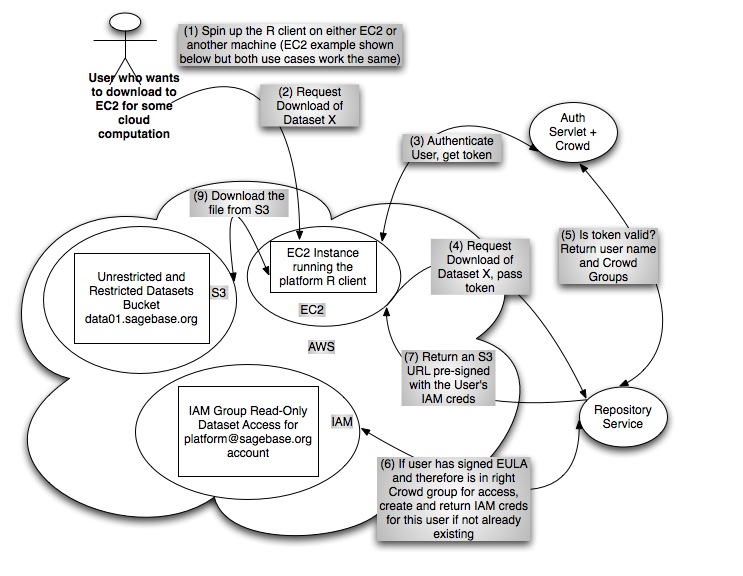
EC2 Cloud Compute Use Case
Elastic MapReduce Use Case
Assumptions
Where
Assume that the initial cloud we target is AWS but we plan to support additional clouds in the future.
For the near term we are using AWS as our external hosting partner. They have agreed to support our efforts for CTCAP. Over time we anticipate adding additional external hosting partners such as Google and Microsoft. We imagine that different scientists and/or institutions will want to take advantage of different clouds.
We can also imagine that the platform should hold locations of files in internal hosting systems, even though not all users of the platform would have access to files in those locations.
Metadata references to hosted data files should be modelled as a collection of Locations, where a Location could be of many types:
- an S3 URL
- a Google Storage URL
- an Azure Blobstore URL
- an EBS snapshot id
- a filepath on a Sage internal server
- ....
| Code Block |
|---|
Class Location
String provider // AWS, Google, Azure, Sage cluster – people will want to set a preferred cloud to work in
String type // filepath, download url, S3 url, EBS snapshot name
String location // the actual uri or path
|
What
For now we are assuming that we are dealing with files. Later on we can also envision providing access to data stored in a database and/or a data warehouse.
We also assume that this data can be stored in S3 in plain text (no encryption).
We also assume that only "unrestricted" and "embargoed" data are hosted by Sage. We assume that "restricted" data is hosted elsewhere such as dbGaP.
Who
Assume tens of thousands of users will eventually use the platform.
How
Assume that users who only want to download do not need to have an AWS account.
Assume that anyone wanting to interact with data on EC2 or Elastic MapReduce will have an AWS account and will be willing to give us their account number (which is a safe piece of info to give out, it is not an AWS credential).
Design Considerations
- metadata
- how to ensure we have metadata for all stuff in the cloud
- file formats
- tar archives or individual files on S3?
- EBS block devices per dataset?
- file layout
- how to organize what we have
- how can we enforce a clean layout for files and EBS volumes?
- how to keep track of what we have
- access patterns
- we want to make the right thing be the easy thing - make it easy to do computation in the cloud
- file download will be supported but will not be the recommended use case
- recommendations and examples from the R prompt for interacting with the data when working on EC2
- security
- not all data is public
- encryption or clear text?
- key management
- one time urls?
- intrusion detection
- how to manage ACLs and bucket policies
- are there scalability upper bounds on ACLs? e.g., can't add more than X AWS accounts to an ACL
- auditability
- how to have audit logs
- how to download them and make use of them
- human data and regulations
- what recommendations do we make to people getting some data from Sage and some data from dbGaP and co-mingling that data in the cloud
- monitoring - what should be monitored
- access patterns
- who
- when
- what
- how much
- data foot print
- upload bandwidth
- download bandwidth
- archive to cheaper storage unused stuff
- cost
- read vs. write
- cost of allowing writes
- cost of keeping same data in multiple formats
- can we take advantage of the free hosting for http://aws.amazon.com/datasets even though we want to keep an audit log?
- how to meter and bill customers for usage
- operations
- how to make it efficient to manage
- reduce the burden of administrative tasks
- how to enable multiple administrators
- how long does it take to get files up/down?
- upload speeds - we are on the lambda rail
- shipping hard drives
- durability
- data corruption
- data loss
- scalability
- if possible, we want to only be the access grantors and then let the hosting provider take care of enforcing access controls and vending data
High Level Use Cases
Users want to:
- download an unrestricted dataset
- download an embargoed dataset for which the platform has granted them access
- use an unrestricted dataset on EC2
- use an embargoed dataset for which the platform has granted them access on EC2
- use an unrestricted dataset on Elastic MapReduce
- use an embargoed dataset for which the platform has granted them access on Elastic MapReduce
There is a more exhaustive list of stuff to consider above but what follows are some firm and some loose requirements:
- enforce access restrictions on datasets
- log downloads
- log EC2/EMR usage
- figure out how to monitor user usage such that we could potentially charge them for usage
- think about how to minimize costs
- think about how to ensure that users sign a EULA before getting access to data
Options to Consider
AWS Public Data Sets
Scenario:
- Sage currently has two data sets stored as "AWS Public Datasets" in the US West Region.
- Users can discover them by browsing public datasets on http://aws.amazon.com/datasets/Biology?browse=1 and also via the platform.
- Users can use them for cloud computation by spinning up EC2 instances and mounting the data as EBS volumes.
- Users cannot directly download data from these public datasets, but once the have them mounted on an EC2 host, they can certainly
scpthem to their local system. - Users cannot directly use these files with Elastic Map Reduce. Instead they would need to first upload them to their own S3 bucket.
- Users are not forced to sign a Sage-specified EULA prior to access since because they can bypass the platform directly and access this data via normal AWS mechanisms.
- Users must have an AWS account to access this data.
- There is no mechanism to grant access. All users with AWS accounts are granted access by default.
- There is no mechanism to keep an audit log for downloads or other usage of this data.
- Users pay for access by paying their own costs for EC2 and bandwidth charges if they choose to download the data out of AWS.
- The cost of hosting is free.
Future Considerations:
- this is currently EBS only but it will also be available for S3 in the future
- TODO ask Deepak what other plans they have in mind for the re-launch of AWS Public Datasets.
- TODO tell Deepak our suggested features for AWS Public Datasets.
Tech Details:
- You create a new "Public Dataset" by
- making an EBS snapshot in each region in which you would like it to be available
- providing the snapshot id(s) and metadata to Deepak (TODO see if this is still the case)
- then you wait for Amazon to get around to it
Pros:
- free hosting!
- scalable
Cons:
- this won't work for public data if it is a requirement that
- all users provide an email address and agree to a EULA prior to access
- we must log downloads
- this won't work for protected data unless the future implementation provides more support
Custom Proxy
All files are kept completely private on S3 and we write a custom proxy that allows users with permission to download files whether to locations outside AWS or to EC2 hosts.
Scenario:
- See details below about the general S3 scenario.
- This would not be compatible with Elastic MapReduce. Users would have to download files to an EC2 host and then store them in their own bucket in S3.
- The platform grants access to the data by facilitating the proxy of their request to S3.
- Users do not need AWS accounts.
- The platform has a custom solution for collecting payment from users to pay for outbound bandwidth when downloading outside the cloud.
Tech Details:
- We would have a fleet of proxy servers running on EC2 hosts that authenticate and authorize users and then proxy download from S3.
- We would need to configure auto-scaling so that capacity for this proxy fleet can grow and shrink as needed.
- We would log events when data access is granted and when data is accessed.
Pros:
- full flexibility
- we can accurately track who has downloaded what when
Cons:
- we have another service fleet to administer
- we are now the scalability bottleneck
S3
Skipping a description of public data on S3 because the scenario is very straightforward - if get the URL you can download the resource. For example: http://s3.amazonaws.com/nicole.deflaux/ElasticMapReduceFun/mapper.R
Unrestricted and Embargoed Data Scenario:
- All Sage data is stored on S3 and is not public.
- Users can only discover what data is available via the platform.
- Users can use the data for cloud computation by spinning up EC2 instances and downloading the files from S3 to the hard drive of their EC2 instance.
- Users can download the data from S3 to their local system.
- The platform directs users to sign a Sage-specified EULA prior to gaining access to these files in S3.
- Users must have a Sage platform account to access this data for download. They may need an AWS account depending upon the mechanism we use to grant access.
- The platform grants access to this data. See below for details about the various ways we might do this.
- The platform will write to the audit log each time it grants access. S3
can also be configured to log all access to resources and this could serve
as a means of records for billing purposes and also intrusion detection.- These two types of logs will have log entries about different events (granting access vs. using access) so they will not have a strict 1-to-1 mapping between entries but should have a substantial overlap.
- The platform can store anything it likes in its audit log.
- The S3 log stores normal web access log type data with the following identifiable fields:
- client IP address is available in the log
- "anonymous" or the user's AWS canonical user id will appear in the log
- We can leave these logs on S3 and run Elastic MapReduce jobs on them
when we need to do data mining. Or we can download them and do data mining locally.
- See proposals below regarding how users might pay for outbound bandwidth.
- The cost of hosting not free.
- Storage fees will apply.
- Data import fees:
- Bandwidth fees apply when data is uploaded.
- Data can also be shipped via hard drives and AWS Import/Export fees would
apply.
- Data export fees:
- Bandwidth fees apply when data is downloaded out of AWS. There is no charge when it is downloaded inside AWS (e.g., to an EC2 instance).
- Data can also be shipped via hard drives and AWS Import/Export fees would
apply.
- These same fees apply to any S3 log data we keep on S3.
Resources:
- Best Effort Server Log Delivery:
- The server access logging feature is designed for best effort. You can expect that most requests against a bucket that is properly configured for logging will result in a delivered log record, and that most log records will be delivered within a few hours of the time that they were recorded.
- However, the server logging feature is offered on a best-effort basis. The completeness and timeliness of server logging is not guaranteed. The log record for a particular request might be delivered long after the request was actually processed, or it might not be delivered at all. The purpose of server logs is to give the bucket owner an idea of the nature of traffic against his or her bucket. It is not meant to be a complete accounting of all requests.
- [Usage Report Consistency
[http://docs.amazonwebservices.com/AmazonS3/2006-03-01/dev/index.html?ServerLogs.html
] ] It follows from the best-effort nature of the server logging feature that the usage reports available at the AWS portal might include usage that does not correspond to any request in a delivered server log.
- I have it on good authority that the S3 logs are accurate but delievery can be delayed now and then
- Log format details
- AWS Credentials Primer
Open Questions:
- can we use the canonical user id to know who the user is if they have
previously given us their AWS account id? No, but we can ask them to provide
their canonical id to us. - if we stick our own query params on the S3 URL will they show up in the S3 log?
Options to Restrict Access to S3
S3 Pre-Signed URLs for Private Content
"Query String Request Authentication Alternative: You can authenticate certain types of requests by passing the required information as query-string parameters instead of using the Authorization HTTP header. This is useful for enabling direct third-party browser access to your private Amazon S3 data, without proxying the request. The idea is to construct a "pre-signed" request and encode it as a URL that an end-user's browser can retrieve. Additionally, you can limit a pre-signed request by specifying an expiration time."
Scenario:
- See above details about the general S3 scenario.
- This would not be compatible with Elastic MapReduce. Users would have to download files to an EC2 host and then store them in their own bucket in S3.
- The platform grants access to the data by creating pre-signed S3 URLs to Sage's private S3 files. These URLs are created on demand and have a short expiry time.
- Users will not need AWS accounts.
- The platform has a custom solution for collecting payment from users to pay for outbound bandwidth when downloading outside the cloud.
Tech Details:
- Repository Service: the service has an API that vends pre-signed S3 URLs for data layer files. Users are authenticated and authorized by the service prior to the service returning a download URL for the layer. The default URL expiry time will be one minute.
- Web Client: When the user clicks on the download button, the web servlet sends a request to the the repository service which constructs and returns a pre-signed S3 URL with an expiry time of one minute. The web servlet returns this URL to the browser as the location value of a 302 redirect. The browser begins download from S3 immediately.
- R Client: When the user Custom Access Log Information "You can include custom information to be stored in the access log record for a request by adding a custom query-string parameter to the URL for the request. Amazon S3 will ignore query-string parameters that begin with "x-", but will include those parameters in the access log record for the request, as part of the Request-URI field of the log record. For example, a GET request for "s3.amazonaws.com/mybucket/photos/2006/08/puppy.jpg?x-user=johndoe" will work the same as the same request for "s3.amazonaws.com/mybucket/photos/2006/08/puppy.jpg", except that the "x-user=johndoe" string will be included in the Request-URI field for the associated log record. This functionality is available in the REST interface only."
Open Questions:
- can we use the canonical user id to know who the user is if they have
previously given us their AWS account id? No, but we can ask them to provide
their canonical id to us. - if we stick our own query params on the S3 URL will they show up in the S3 log? - YES see above naming convention
Options to Restrict Access to S3
S3 Pre-Signed URLs for Private Content
"Query String Request Authentication Alternative: You can authenticate certain types of requests by passing the required information as query-string parameters instead of using the Authorization HTTP header. This is useful for enabling direct third-party browser access to your private Amazon S3 data, without proxying the request. The idea is to construct a "pre-signed" request and encode it as a URL that an end-user's browser can retrieve. Additionally, you can limit a pre-signed request by specifying an expiration time."
Scenario:
- See above details about the general S3 scenario.
- This would not be compatible with Elastic MapReduce. Users would have to download files to an EC2 host and then store them in their own bucket in S3.
- The platform grants access to the data by creating pre-signed S3 URLs to Sage's private S3 files. These URLs are created on demand and have a short expiry time.
- Users will not need AWS accounts.
- The platform has a custom solution for collecting payment from users to pay for outbound bandwidth when downloading outside the cloud.
Tech Details:
- Repository Service: the service has an API that vends pre-signed S3 URLs for data layer files. Users are authenticated and authorized by the service prior to the service returning a download URL for the layer. The default URL expiry time will be one minute.
- Web Client: When the user clicks on the download button, the web servlet sends a request to the the repository service which constructs and returns a pre-signed S3 URL with an expiry time of one minute. The web servlet returns this URL to the browser as the location value of a 302 redirect. The browser begins download from S3 immediately.
- R Client: When the user issues the download command at the R prompt, the R client sends a request to the the repository service which constructs and returns a pre-signed S3 URL with an expiry time of one minute. The R client uses the returned URL to begin to download the content from S3 immediately.
...
- The repository service grants access by adding the user to the correct Crowd and IAM groups for the desired dataset. The Crowd groups are "the truth" and the IAM groups are a mirror of that.At access grant time, we also have to determine and store the mapping between IAM id and canonical user id. The S3 team has a fix for this on their roadmap but in the interim we have to make a request for a particular known URL as that new user and then retreive the canonical id from the S3 log and store it in our system.mirror of that.
- Log data
- For IAM user
nicole.deflauxmy identity is recorded in the log asarn:aws:iam::325565585839:user/nicole.deflaux - Not that IAM usernames can be email addresses so that we can easily reconcile them with their email addresses registered with the platform -> because we will use the email they gave us when we create their IAM user.
- Here is what a full log entry looks like:
Code Block d9df08ac799f2859d42a588b415111314cf66d0ffd072195f33b921db966b440 data01.sagebase.org [18/Feb/2011:19:32:56 +0000] 140.107.149.246 arn:aws:iam::325565585839:user/nicole.deflaux C6736AEED375F69E REST.GET.OBJECT human_liver_cohort/readme.txt "GET /data01.sagebase.org/human_liver_cohort/readme.txt?AWSAccessKeyId=AKIAJBHAI75QI6ANOM4Q&Expires=1298057875&Signature=XAEaaPtHUZPBEtH5SaWYPMUptw4%3D&x-amz-security-token=AQIGQXBwVGtupqEus842na80zMbEFbfpPhOsIic7z1ghm0Umjd8kybj4eaOtBCKlwVHMXi2SuasIKxwYljjDA95O%2BfZb5uF7ku4crE6OObz8d/ev7ArPime2G/a5nXRq56Jx2hAt8NDDbhnE8JqyOnKn%2BN308wx2Ud3Q2R3rSqK6t%2Bq/l0UAkhBFNM1gvjR%2BoPGYBV9Jspwfp8ww8CuZVH1Y2P2iid6ZS93K02sbGvQnhU7eCGhorhMI5kxOqy7bTbzvl2HML7zQphXRIa1wqrRSD/sBLfpK5x6A%2BcQnLrgO6FtWJMDo5rTmgEPo6esNIivWnaiI6BvPddLlBMZVtmcx39/cOBbrfK3v0vHmYb3oftseacjvBD/wfyigB5wbSgRUYNhbUu1V HTTP/1.1" 200 - 6300 6300 45 45 "https://s3-console-us-standard.console.aws.amazon.com/GetResource/Console.html?&lpuid=AIDAJDFZWQHFC725MCNDW&lpfn=nicole.deflaux&lpgn=325565585839&lpas=ACTIVE&lpiamu=t&lpak=AKIAJBHAI75QI6ANOM4Q&lpst=AQIGQXBwVGtupqEus842na80zMbEFbfpPhOsIic7z1ghm0Umjd8kybj4eaOtBCKlwVHMXi2SuasIKxwYljjDA95O%2BfZb5uF7ku4crE6OObz8d%2Fev7ArPime2G%2Fa5nXRq56Jx2hAt8NDDbhnE8JqyOnKn%2BN308wx2Ud3Q2R3rSqK6t%2Bq%2Fl0UAkhBFNM1gvjR%2BoPGYBV9Jspwfp8ww8CuZVH1Y2P2iid6ZS93K02sbGvQnhU7eCGhorhMI5kxOqy7bTbzvl2HML7zQphXRIa1wqrRSD%2FsBLfpK5x6A%2BcQnLrgO6FtWJMDo5rTmgEPo6esNIivWnaiI6BvPddLlBMZVtmcx39%2FcOBbrfK3v0vHmYb3oftseacjvBD%2FwfyigB5wbSgRUYNhbUu1V&lpts=1298051257585" "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_6; en-US) AppleWebKit/534.13 (KHTML, like Gecko) Chrome/9.0.597.102 Safari/534.13" -
- For IAM user
- The repository service vends credentials for the users' use.
- Users will need to sign those S3 URLs with their AWS credentials using the usual toolkit provided by Amazon.
- One example tool provided by Amazon is s3curl
- I'm sure we can also get the R client to also do the signing. We can essential hide the fact that users have their own credentials just for this since the R client can communicate with the repository service and cache credentials in memory.
- We may be able to find a JavaScript library to do the signing as well for Web client use cases. If not, we could proxy download requests. That solution is described in its own section below.
...
The Pacific Northwest Gigapop is the point of presence for the Internet2/Abilene network in the Pacific Northwest. The PNWGP is connected to the Abilene backbone via a 10 GbE link. In turn, the Abilene Seattle node is connected via OC-192 192 links to both Sunnyvale, California and Denver, Colorado.
PNWPG offers two types of Internet2/Abilene interconnects: Internet2/Abilene transit services and Internet2/Abilene peering at Pacific Wave International Peering Exchange. See Participant Services for more information.
...