...
At the highest level, the Synapse REST API is supported from a single two separate war file files deployed to Amazon's Elastic Beanstalk call . The first war provides all web-services for the REST API and is called the repository.war. While the repository services reads data from many sources including RDS (MySQL), S3, CloudSearch, Dynamo, SQS, it will only write to RDS and S3.The second war builds all secondary index data used by repository services and is called the worker.war. All "truth" data of Synapse resides in RDS and S3. This truth data is written directly from the repository when a Create, Update, or Delete web-services is called. After writing the truth data to RDS or S3, the repository service will broadcast a change message to an Amazon SNS Topic. A worker from the workers.war will then pickup the change massages and update one or more of the secondary indexes. The relationship is shown in the following diagram:
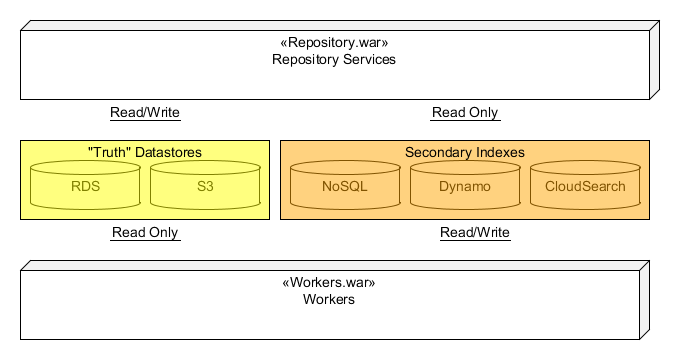
Any REST call that writes data from the repository services will always be in a single database transaction. This includes writes where data is stored in S3. For such cases, data is first written to S3 using a key containing a UUID. The key is then stored in RDS as part of the single transaction. This means any S3 data or RDS data will always have read/write consistency. All other secondary data sources will be eventual consistent.
...
As mentioned above, the repository services only writes to RDS and S3. All other data-sources (Dynamo, CloudSearch, etc.) are secondary and serve as indexes for quick data retrieval for things such as ad hock queries and search. These secondary indexes are populated by a secondary application called "workers"the workers in the workers.war. The details of these worker will be covered more detail later, but for now, think of the workers as a suite of processes that respond to messages generated by the repository services.
...